1. 什么是RAGFlow? #
RAGFlow 是一个基于 RAG(检索增强生成)技术的开源 AI 应用解决方案。它通过可视化的方式,让开发者甚至是非技术背景的业务专家,都能快速构建出高质量的、基于私有知识的智能问答、文档分析和内容生成系统。
1.1 生活中的类比 #
想象一下,你想建一个智能客服系统,让用户可以通过提问的方式快速找到产品文档中的信息。
传统方法:
- 需要编写大量代码
- 需要理解复杂的RAG技术细节
- 调试和优化困难
- 需要专业的开发人员
使用RAGFlow:
- 通过可视化界面拖拽组件
- 无需编写代码
- 直观地调试和优化
- 非技术人员也能使用
RAGFlow 就像是一个"可视化编程工具",让你用拖拽的方式构建RAG系统,而不需要写代码。
1.2 RAGFlow的核心定位 #
RAGFlow 的定位是:一个降低了技术门槛的、企业级的、高性能的 RAG 应用开发平台。
核心特点:
- 可视化工作流:通过图形界面设计和优化RAG流程
- 深度文档理解:支持文本、表格、图片等多种格式
- 精准引用溯源:每个答案都标注来源,可追溯可核实
- 开源自主可控:完全开源,可私有化部署
1.3 为什么选择RAGFlow? #
vs 传统RAG开发:
- 传统方式需要编写大量代码,RAGFlow提供可视化界面
- 传统方式调试困难,RAGFlow可以直观地看到每个步骤
- 传统方式需要专业知识,RAGFlow降低了使用门槛
vs 商用闭源平台:
- 商用平台通常需要付费,RAGFlow完全免费开源
- 商用平台数据可能上云,RAGFlow可私有化部署
- 商用平台功能受限,RAGFlow可以完全自定义
2. 安装 #
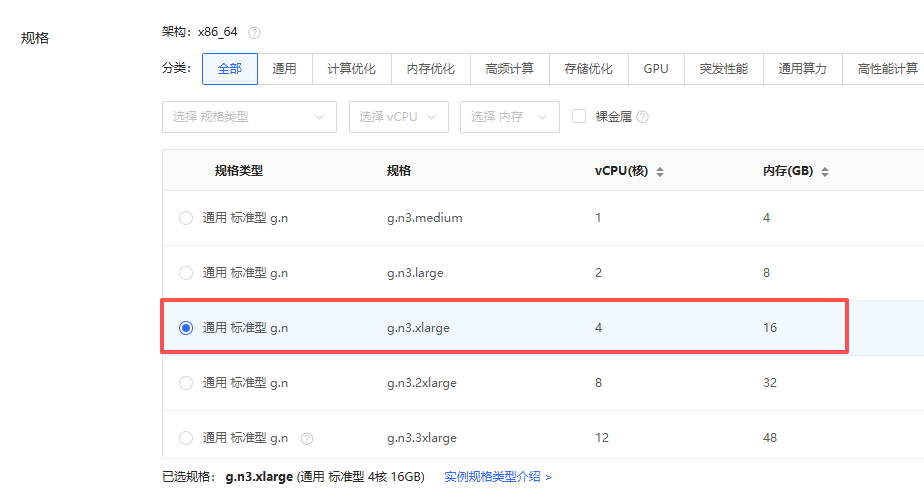
2.1 购买 #
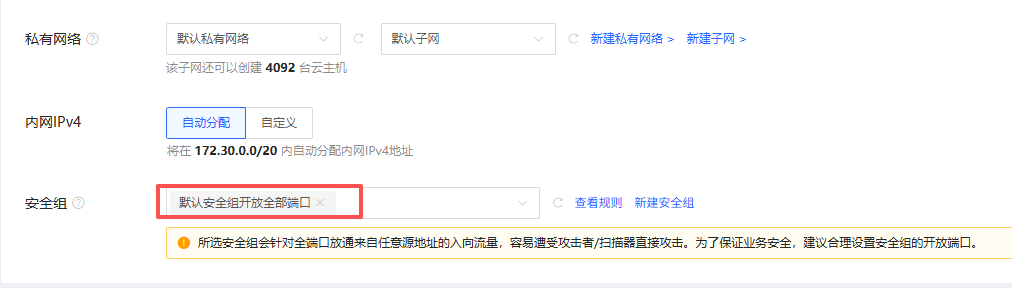
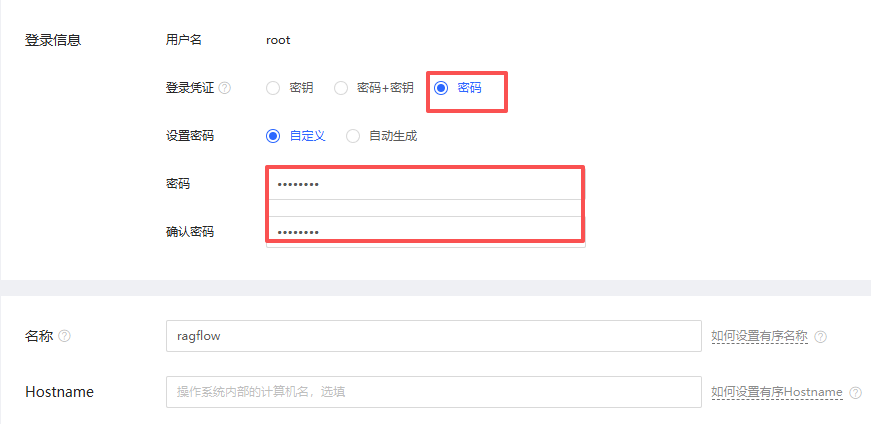
2.2 按量付费 #


2.3 登录服务器 #
2.3.1 使用shell #
ssh root@IP2.3.2 使用xshell #
2.4 安装宝塔面板 #
wget -O install_panel.sh https://download.bt.cn/install/install_panel.sh && sudo bash install_panel.sh ssl251104Congratulations! Installed successfully!
请选择以下其中一种方式解决不安全提醒
1、下载证书,地址:https://dg2.bt.cn/ssl/baota_root.pfx,双击安装,密码【www.bt.cn】
2、点击【高级】-【继续访问】或【接受风险并继续】访问
教程:https://www.bt.cn/bbs/thread-117246-1-1.html
mac用户请下载使用此证书:https://dg2.bt.cn/ssl/mac.crt
【云服务器】请在安全组放行 29978 端口
外网ipv4面板地址: https://116.198.44.106:29978/8f9314b9
内网面板地址: https://172.30.0.6:29978/8f9314b9
username: mngxhwjr
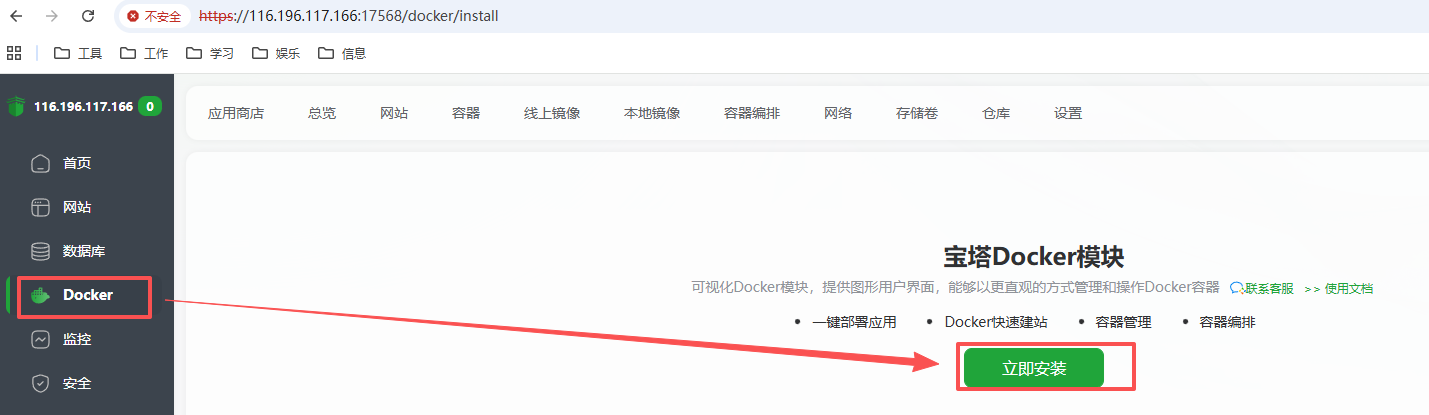
password: 9811737a2.5 安装docker #
访问登录 https://116.198.44.106:29978/8f9314b9 username: mngxhwjr password: 9811737a
使用宝塔面板安装docker
2.6 启动ragflow #
2.6.1 下载代码 #
$ git clone https://gitee.com/bopisky/ragflow.git
$ cd ragflow
$ git checkout -f v0.20.5
$ cd docker2.6.2修改.env文件 #
修改docker目录下面的.env文件
把
RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.5-slim改为
RAGFLOW_IMAGE=infiniflow/ragflow:v0.20.52.6.3 启动服务 #
docker compose -f docker-compose.yml up -d2.7 访问 #
可以通过 http://IP 访问ragflow
2.7 ragflow-plus #
#宝塔面板-v9.6.0git clone https://gitee.com/yakou/ragflow-plus
docker compose -f docker/docker-compose.yml up -d# 拉取 ollama 镜像
docker pull docker.1ms.run/ollama/ollama
# 后台运行 ollama 容器,将本地 /data/ollama 挂载到容器内部,暴露 11434 端口
docker run --rm -d -v /data/ollama:/root/.ollama -p 11434:11434 --name ollama docker.1ms.run/ollama/ollama
# 聊天模型:运行 deepseek-r1:1.5b
docker exec -it ollama ollama run deepseek-r1:1.5b
# 向量化模型:拉取 bge-m3:latest
docker exec -it ollama ollama pull bge-m3:latest
# 重排序模型:拉取 xitao/bge-reranker-v2-m3
docker exec -it ollama ollama pull xitao/bge-reranker-v2-m3
# 图像转文本模型:拉取 llava:7b
docker exec -it ollama ollama pull llava:7b
OPENAI_API_KEY=d52e49a1-36ea-44bb-bc6e-65ce789a72f6
OPENAI_BASE_URL=https://ark.cn-beijing.volces.com/api/v3/chat/completions
# 测试 API 连通性
curl -X POST https://ark.cn-beijing.volces.com/api/v3/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer d52e49a1-36ea-44bb-bc6e-65ce789a72f6" \
-d '{
"model": "doubao-seed-1-6-250615",
"messages": [{"role": "user", "content": "Hello"}]
}'
# 设置文本向量API的URL
VOLC_EMBEDDINGS_API_URL = "https://ark.cn-beijing.volces.com/api/v3/embeddings"
# 设置API密钥
VOLC_API_KEY = "d52e49a1-36ea-44bb-bc6e-65ce789a72f6"
doubao-embedding-text-240715
curl -X POST "https://ark.cn-beijing.volces.com/api/v3/embeddings" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer d52e49a1-36ea-44bb-bc6e-65ce789a72f6" \
-d '{
"model": "doubao-embedding-text-240715",
"input": "需要转换为向量的文本内容"
}'
deepseek sk-ca18836faa314001842482780ac0d43c
siliconflow sk-sdpjzvkdzzujfvtxwyjenkssjdcycituosdoxnzmlnxkaawe| 模型名称 | 类型 | 开发组织 | 备注 |
|---|---|---|---|
| 聊天模型 (Chat) | |||
| 01-ai/Yi-1.5-34B-Chat-16K | chat | 01.ai | 340亿参数,16K上下文 |
| 01-ai/Yi-1.5-6B-Chat | chat | 01.ai | 60亿参数 |
| 01-ai/Yi-1.5-9B-Chat-16K | chat | 01.ai | 90亿参数,16K上下文 |
| deepseek-ai/DeepSeek-R1 | chat | DeepSeek | 推理模型 |
| deepseek-ai/DeepSeek-V3 | chat | DeepSeek | 通用对话 |
| deepseek-ai/deepseek-vl2 | chat | DeepSeek | 视觉语言模型 |
| google/gemma-2-27b-it | chat | 270亿参数 | |
| google/gemma-2-9b-it | chat | 90亿参数 | |
| internlm/internlm2_5-20b-chat | chat | InternLM | 200亿参数 |
| internlm/internlm2_5-7b-chat | chat | InternLM | 70亿参数 |
| meta-llama/Llama-3.3-70B-Instruct | chat | Meta | 700亿参数 |
| meta-llama/Meta-Llama-3.1-405B-Instruct | chat | Meta | 4050亿参数 |
| meta-llama/Meta-Llama-3.1-70B-Instruct | chat | Meta | 700亿参数 |
| meta-llama/Meta-Llama-3.1-8B-Instruct | chat | Meta | 80亿参数 |
| Qwen/Qwen1.5-32B-Chat | chat | Qwen | 320亿参数 |
| Qwen/Qwen1.5-7B-Chat | chat | Qwen | 70亿参数 |
| Qwen/Qwen2-1.5B-Instruct | chat | Qwen | 15亿参数 |
| Qwen/Qwen2-7B-Instruct | chat | Qwen | 70亿参数 |
| Qwen/Qwen2-Math-72B-Instruct | chat | Qwen | 720亿参数,数学专用 |
| Qwen/Qwen2.5-14B-Instruct | chat | Qwen | 140亿参数 |
| Qwen/Qwen2.5-32B-Instruct | chat | Qwen | 320亿参数 |
| Qwen/Qwen2.5-72B-Instruct | chat | Qwen | 720亿参数 |
| Qwen/Qwen2.5-72B-Instruct-128K | chat | Qwen | 720亿参数,128K上下文 |
| Qwen/Qwen2.5-7B-Instruct | chat | Qwen | 70亿参数 |
| Qwen/QwQ-32B | chat | Qwen | 320亿参数 |
| Qwen/QwQ-32B-Preview | chat | Qwen | 320亿参数预览版 |
| THUDM/chatglm3-6b | chat | THUDM | 60亿参数 |
| THUDM/glm-4-9b-chat | chat | THUDM | 90亿参数 |
| 蒸馏模型 (Distill) | |||
| deepseek-ai/DeepSeek-R1-Distill-Llama-70B | chat | DeepSeek | 基于Llama的70B蒸馏 |
| deepseek-ai/DeepSeek-R1-Distill-Llama-8B | chat | DeepSeek | 基于Llama的8B蒸馏 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | chat | DeepSeek | 基于Qwen的1.5B蒸馏 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-14B | chat | DeepSeek | 基于Qwen的14B蒸馏 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | chat | DeepSeek | 基于Qwen的32B蒸馏 |
| deepseek-ai/DeepSeek-R1-Distill-Qwen-7B | chat | DeepSeek | 基于Qwen的7B蒸馏 |
| 嵌入模型 (Embedding) | |||
| BAAI/bge-large-en-v1.5 | embedding | BAAI | 英文嵌入模型 |
| BAAI/bge-large-zh-v1.5 | embedding | BAAI | 中文嵌入模型 |
| BAAI/bge-m3 | embedding | BAAI | 多语言嵌入 |
| netease-youdao/bce-embedding-base_v1 | embedding | 网易有道 | 基础嵌入 |
| Qwen/Qwen3-Embedding-0.6B | embedding | Qwen | 6亿参数 |
| Qwen/Qwen3-Embedding-4B | embedding | Qwen | 40亿参数 |
| Qwen/Qwen3-Embedding-8B | embedding | Qwen | 80亿参数 |
| 重排模型 (Rerank) | |||
| BAAI/bge-reranker-v2-m3 | rerank | BAAI | 多语言重排 |
| netease-youdao/bce-reranker-base_v1 | rerank | 网易有道 | 基础重排 |
| 图像转文本 (Image2Text) | |||
| deepseek-ai/Janus-Pro-7B | image2text | DeepSeek | 70亿参数 |
| Qwen/QVQ-72B-Preview | image2text | Qwen | 720亿参数预览版 |
| 语音合成 (TTS) | |||
| fishaudio/fish-speech-1.5 | tts | FishAudio | 语音合成 |
| FunAudioLLM/CosyVoice2-0.5B | tts | FunAudioLLM | 5亿参数 |
| Pro版本模型 | |||
| Pro/01-ai/Yi-1.5-6B-Chat | chat | 01.ai | Pro版本 |
| Pro/deepseek-ai/DeepSeek-R1 | chat | DeepSeek | Pro版本 |
| Pro/deepseek-ai/DeepSeek-V3 | chat | DeepSeek | Pro版本 |
| Pro/google/gemma-2-9b-it | chat | Pro版本 | |
| Pro/meta-llama/Meta-Llama-3.1-8B-Instruct | chat | Meta | Pro版本 |
| Pro/Qwen/Qwen2-1.5B-Instruct | chat | Qwen | Pro版本 |
| Pro/Qwen/Qwen2-7B-Instruct | chat | Qwen | Pro版本 |
| Pro/Qwen/Qwen2.5-7B-Instruct | chat | Qwen | Pro版本 |
| Pro/Qwen/Qwen2.5-Coder-7B-Instruct | chat | Qwen | 代码专用Pro版 |
| Pro/THUDM/glm-4-9b-chat | chat | THUDM | Pro版本 |
3. RAGFlow的核心特性 #
3.1 深度文档理解 #
RAGFlow不仅能处理纯文本,还能理解复杂的文档结构。
支持的文档格式:
- 文本文件:TXT、Markdown等
- Office文档:Word、Excel、PowerPoint
- PDF文档:支持文字和图片提取
- 图片文件:支持OCR文字识别
深度理解能力:
- 表格解析:能理解表格的结构和行列关系
- 图片识别:能提取图片中的文字信息
- 结构化提取:能识别文档的章节、段落等结构
3.2 可视化工作流编排 #
RAGFlow最大的亮点是可视化的工作流编排界面。
工作流组件:
- 文档加载器:加载各种格式的文档
- 文本分割器:将长文本切分成小块
- 向量化器:将文本转换为向量
- 检索器:从向量库中检索相关文档
- 生成器:基于检索结果生成答案
可视化优势:
- 直观地看到整个流程
- 轻松调整参数和配置
- 快速测试不同策略
- 无需编写代码
3.3 精准引用与溯源 #
RAGFlow生成的每个答案都会标注来源。
引用信息包括:
- 文档名称:答案来自哪份文档
- 页码位置:答案来自文档的哪一页
- 原文片段:答案对应的原文内容
溯源的价值:
- 增加答案的可信度
- 方便用户核实信息
- 符合企业合规要求
4. RAGFlow的工作原理 #
4.1 知识库入库流程 #
RAGFlow的知识库入库流程包括以下步骤:
步骤1:文档加载
- 用户上传文档(PDF、Word、PPT等)
- RAGFlow解析文档,提取文本、表格、图片等内容
步骤2:文档解析
- 深度解析文档结构
- 识别章节、段落、表格等元素
- 提取图片中的文字(OCR)
步骤3:文本切分
- 根据设定的规则切分文本
- 可以按段落、按章节、按固定长度等
- 确保每个文本块包含完整语义
步骤4:向量化
- 使用嵌入模型将文本块转换为向量
- 语义相近的文本,向量距离也相近
步骤5:向量存储
- 将向量存入向量数据库(如Milvus)
- 同时保存原始文本和元数据
4.2 问答检索流程 #
用户提问时,RAGFlow的问答流程如下:
步骤1:问题向量化
- 将用户问题转换为向量
- 使用与入库时相同的嵌入模型
步骤2:语义检索
- 在向量数据库中搜索相似向量
- 返回Top-K个最相关的文本块
步骤3:结果重排(可选)
- 对检索结果进行二次排序
- 可以使用关键词匹配、BM25等方法
步骤4:构建提示词
- 将问题和检索到的文本块组合
- 格式:"请根据以下信息回答问题:[文本块1]...[文本块N]。问题是:[用户问题]"
步骤5:生成答案
- 调用大语言模型生成答案
- 支持OpenAI、本地模型等多种LLM
步骤6:返回结果
- 返回生成的答案
- 同时返回引用的原文片段和来源信息
5. RAGFlow的主要应用场景 #
5.1 企业智能知识库 #
企业可以将内部文档导入RAGFlow,构建智能知识库。
应用场景:
- 员工可以快速查找公司制度、产品手册等信息
- 新员工培训,快速了解公司知识
- 技术支持,快速定位解决方案
优势:
- 无需记忆大量文档内容
- 快速找到相关信息
- 答案可追溯,可信度高
5.2 法律与合同审查 #
法律行业可以使用RAGFlow快速查找相关法条和案例。
应用场景:
- 律师查找相关法律条文
- 法务审查合同,查找相似案例
- 法律研究,快速定位相关理论
优势:
- 提高工作效率
- 减少遗漏重要信息
- 答案有明确来源
5.3 技术支持和客服 #
可以基于产品文档构建智能客服系统。
应用场景:
- 用户提问产品使用问题
- 技术支持查找故障解决方案
- 客服快速回答常见问题
优势:
- 24小时在线服务
- 回答准确一致
- 可以引用具体文档
6. 与其他工具的对比 #
6.1 vs LangChain / LlamaIndex #
| 特性 | RAGFlow | LangChain / LlamaIndex |
|---|---|---|
| 使用方式 | 可视化界面 | 代码编程 |
| 上手难度 | 较低 | 较高 |
| 灵活性 | 高(通过界面配置) | 极高(代码实现) |
| 适用人群 | 技术人员和非技术人员 | 主要是开发人员 |
| 文档理解 | 内置支持表格、图片 | 需要额外编码 |
选择建议:
- 选择RAGFlow:快速原型开发、非技术人员使用、需要可视化调试
- 选择LangChain:需要高度定制、复杂业务逻辑、有开发团队
6.2 vs 商用闭源平台 #
| 特性 | RAGFlow | 商用闭源平台 |
|---|---|---|
| 成本 | 免费开源 | 通常需要付费 |
| 数据控制 | 完全自主 | 可能依赖厂商 |
| 部署方式 | 可私有化部署 | 通常为SaaS |
| 定制能力 | 完全开源可定制 | 受平台限制 |
| 技术支持 | 社区支持 | 厂商支持 |
选择建议:
- 选择RAGFlow:注重数据安全、需要私有化部署、预算有限
- 选择商用平台:需要专业支持、快速上线、不关心数据隐私