1. Milvus简介 #
1.1 Milvus是什么? #
Milvus是一种向量数据库,它是专门设计来存储和搜索大量向量数据的。
1.2 为什么Milvus这么流行? #
- 超级快:Milvus可以在几毫秒内从数十亿个向量中找到最相似的向量
- 开源免费:任何人都可以使用它,不需要付费
- 容易使用:即使不是专业程序员也能学会使用它
1.3 Milvus能做什么? #
- 图片搜索:上传一张照片,Milvus能找到相似的图片
- 语音识别:说一句话,Milvus能理解你的意思
- 推荐系统:根据你喜欢的电影,推荐你可能喜欢的其他电影
- 智能问答:问一个问题,找到最相关的答案
1.4 Milvus是如何工作的? #
- 收集数据:把图片、文字、声音等转换成向量(数字列表)
- 存储向量:把这些向量存储在数据库中
- 快速搜索:当你需要查找相似内容时,Milvus能快速找到最相似的向量
2. Milvus的安装 #
2.1 下载docker-compose.yml文件 #
2.1.1 Windows #
C:\>Invoke-WebRequest https://github.com/milvus-io/milvus/releases/download/v2.4.15/milvus-standalone-docker-compose.yml -OutFile docker-compose.yml
如果访问不了可以使用
C:\>Invoke-WebRequest https://gitee.com/milvus-io/milvus/raw/v2.6.4/deployments/docker/standalone/docker-compose.yml -OutFile docker-compose.yml
docker compose up -d
docker compose ps
NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS
milvus-etcd quay.io/coreos/etcd:v3.5.5 "etcd -advertise-cli…" etcd 15 seconds ago Up 10 seconds (health: starting) 2379-2380/tcp
milvus-minio minio/minio:RELEASE.2023-03-20T20-16-18Z "/usr/bin/docker-ent…" minio 15 seconds ago Up 9 seconds (health: starting) 0.0.0.0:9000-9001->9000-9001/tcp
milvus-standalone milvusdb/milvus:v2.4.15 "/tini -- milvus run…" standalone 14 seconds ago Up 8 seconds (health: starting) 0.0.0.0:9091->9091/tcp, 0.0.0.0:19530->19530/tcp2.1.2 MAC 或 Linux #
wget https://gitee.com/milvus-io/milvus/raw/v2.6.4/deployments/docker/standalone/docker-compose.yml -O docker-compose.yml
docker compose up -d2.2 docker-compose.yml文件 #
# 指定Docker Compose文件格式版本为3.5
version: '3.5'
# 定义服务组
services:
# etcd服务配置,用于Milvus的元数据存储
etcd:
# 容器名称设置为milvus-etcd
container_name: milvus-etcd
# 使用coreos的etcd镜像,版本为v3.5.5
image: quay.io/coreos/etcd:v3.5.5
# 设置etcd的环境变量
environment:
# 设置自动压缩模式为revision
- ETCD_AUTO_COMPACTION_MODE=revision
# 设置自动压缩保留1000个版本
- ETCD_AUTO_COMPACTION_RETENTION=1000
# 设置后端存储配额为4GB
- ETCD_QUOTA_BACKEND_BYTES=4294967296
# 设置快照计数为50000
- ETCD_SNAPSHOT_COUNT=50000
# 挂载卷,将本地目录映射到容器内的/etcd目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/etcd:/etcd
# 启动命令,配置etcd服务器
command: etcd -advertise-client-urls=http://127.0.0.1:2379 -listen-client-urls http://0.0.0.0:2379 --data-dir /etcd
# 健康检查配置
healthcheck:
# 使用etcdctl检查端点健康状态
test: ["CMD", "etcdctl", "endpoint", "health"]
# 每30秒检查一次
interval: 30s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# MinIO服务配置,用于Milvus的对象存储
minio:
# 容器名称设置为milvus-minio
container_name: milvus-minio
# 使用MinIO镜像,指定版本
image: minio/minio:RELEASE.2023-03-20T20-16-18Z
# 设置MinIO的环境变量
environment:
# 设置访问密钥
MINIO_ACCESS_KEY: minioadmin
# 设置密钥
MINIO_SECRET_KEY: minioadmin
# 端口映射,将容器的9001和9000端口映射到主机
ports:
- "9001:9001"
- "9000:9000"
# 挂载卷,将本地目录映射到容器内的/minio_data目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/minio:/minio_data
# 启动命令,配置MinIO服务器和控制台地址
command: minio server /minio_data --console-address ":9001"
# 健康检查配置
healthcheck:
# 使用curl检查MinIO健康状态
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
# 每30秒检查一次
interval: 30s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# Milvus独立服务配置
standalone:
# 容器名称设置为milvus-standalone
container_name: milvus-standalone
# 使用Milvus镜像,版本为v2.4.15
image: milvusdb/milvus:v2.4.15
# 启动命令,以独立模式运行Milvus
command: ["milvus", "run", "standalone"]
# 安全选项配置
security_opt:
# 禁用seccomp配置文件
- seccomp:unconfined
# 设置Milvus的环境变量
environment:
# 设置etcd端点地址
ETCD_ENDPOINTS: etcd:2379
# 设置MinIO地址
MINIO_ADDRESS: minio:9000
# 挂载卷,将本地目录映射到容器内的/var/lib/milvus目录
volumes:
- ${DOCKER_VOLUME_DIRECTORY:-.}/volumes/milvus:/var/lib/milvus
# 健康检查配置
healthcheck:
# 使用curl检查Milvus健康状态
test: ["CMD", "curl", "-f", "http://localhost:9091/healthz"]
# 每30秒检查一次
interval: 30s
# 启动后等待90秒开始检查
start_period: 90s
# 超时时间为20秒
timeout: 20s
# 重试3次
retries: 3
# 端口映射,将容器的19530和9091端口映射到主机
ports:
- "19530:19530"
- "9091:9091"
# 依赖关系,确保etcd和minio服务先启动
depends_on:
- "etcd"
- "minio"
# 网络配置
networks:
# 默认网络配置
default:
# 网络名称设置为milvus
name: milvus2.3 配置docker镜像 #
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://fwvjnv59.mirror.aliyuncs.com",
"https://docker.m.daocloud.io",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://noohub.ru"
]
}3. Milvus的图形界面 #
Attu是一个帮助我们使用Milvus向量数据库的图形界面工具
3.1 Attu能做什么? #
- 查看数据:看到存储在Milvus中的所有集合(可以理解为表格)和向量数据
- 创建集合:建立新的数据存储空间
- 导入数据:把数据添加到Milvus中
- 搜索相似内容:找到与某个向量最相似的其他向量
- 管理数据库:监控数据库的运行状态和性能
3.2 如何使用Attu? #
- 首先确保Milvus已经运行起来了
- 打开网页浏览器,访问Attu的地址(通常是http://localhost:8000)
- 连接到你的Milvus服务器
- 然后你就可以开始浏览和管理你的向量数据了!
4. 使用Attu连接Milvus #
这条命令用于启动Attu,它是Milvus向量数据库的图形用户界面工具
docker run -p 8000:3000 -e MILVUS_URL=192.168.2.106:19530 zilliz/attu:v2.5
http://192.168.2.106:8000/#/一定要注意MILVUS_URL后面跟着的IP地址要改成自己的IP地址,这个IP地址如果是Windows可以使用ipconfig命令获取,如果是Linux和MAC可以使用ifconfig命令获取
1. docker run
- 这是基本的Docker命令,用于创建并启动一个新的容器
2. -p 8000:3000
- 这是端口映射参数
- 将主机的8000端口映射到容器内的3000端口
- 这意味着当你访问主机的8000端口时,请求会被转发到容器内的3000端口
- Attu的Web界面在容器内运行在3000端口
3. -e MILVUS_URL=192.168.2.106:19530
-e表示设置环境变量MILVUS_URL=192.168.2.106:19530指定了Milvus服务器的地址和端口192.168.2.106是Milvus服务器的IP地址19530是Milvus服务的默认端口
4. zilliz/attu:v2.5
- 这是Docker镜像的名称和标签
zilliz/attu是镜像名称,由Zilliz公司(Milvus的开发者)提供v2.5是版本标签,表示使用Attu的2.5版本
5. 访问地址
http://192.168.2.106:8000/#/这是启动Attu后的访问地址:
http://是协议192.168.2.106是主机IP地址8000是我们映射的端口/#/是Attu应用的路径
这个命令做了以下事情:
- 从Docker Hub下载并运行Attu工具(如果本地没有)
- 将Attu连接到指定IP地址的Milvus数据库
- 设置端口映射,让你可以通过浏览器访问Attu的界面
- 提供一个网址,通过这个网址你可以在浏览器中打开Attu管理界面
通过Attu界面,你可以直观地管理Milvus数据库中的向量数据,包括创建集合、导入数据、执行向量搜索等操作。
5. 创建数据库 #
5.1 创建集合 #
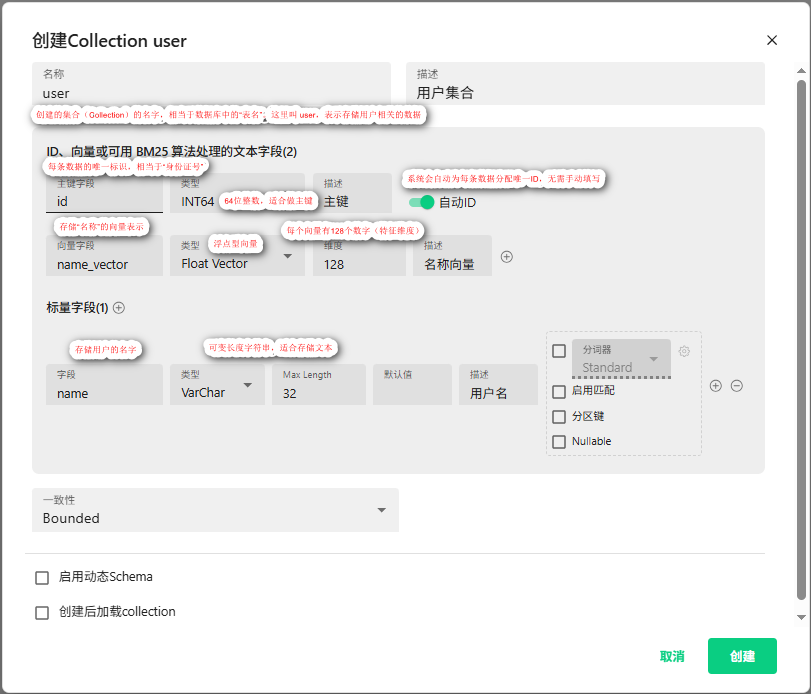
基本信息
- 集合名称:user
- 集合描述:用户
字段配置 界面显示了三种主要字段类型的配置:
ID字段(主键)
- 字段名称:id
- 数据类型:INT64
- 描述:主键
- 特性:自动ID(已启用)
- 说明:ID
向量字段
- 字段名称:name_vector
- 数据类型:Float Vector
- 维度:128
- 描述:用户名向量
- 功能:用于存储向量数据,支持向量相似度搜索
标量字段
- 字段名称:name
- 数据类型:VarChar
- 最大长度:32
- 分词器:Standard(标准分词器)
- 可选配置:
- 启用匹配(未选中)
- 分区键(未选中)
- Nullable(未选中)
集合属性设置
- 一致性模式:Bounded(有界一致性)
- 其他选项:
- 启用动态Schema(未选中)
- 创建后加载collection(未选中)
| 类型类别 | 类型名称 | 说明/用途 |
|---|---|---|
| 主键字段 | INT64 | 64位整数,常用于自增ID、编号等唯一标识。 |
| VARCHAR | 可变长度字符串,适合用作唯一标识的文本(如用户名、邮箱等)。 | |
| 向量字段 | Binary Vector | 二进制向量,常用于图像、音频等二进制特征的检索。 |
| Float Vector | 浮点型向量,最常见的AI特征向量类型(如文本、图片的嵌入向量)。 | |
| Float16 Vector | 16位浮点向量,节省存储空间,适合大规模数据。 | |
| BFloat16 Vector | 另一种16位浮点格式,兼容AI硬件加速。 | |
| Sparse Vector | 稀疏向量,适合大部分元素为0的高维特征(如文本one-hot编码)。 | |
| BM25(Varchar) | 文本字段,支持BM25等关键词检索算法。 | |
| 标量字段 | Int8 | 8位整数,节省空间,适合小范围数字。 |
| Int16 | 16位整数。 | |
| Int32 | 32位整数。 | |
| Int64 | 64位整数。 | |
| Float | 单精度浮点数。 | |
| Double | 双精度浮点数,精度更高。 | |
| Boolean | 布尔值,只有true/false。 | |
| VarChar | 可变长度字符串,适合存储文本(如名字、描述等)。 | |
| JSON | 存储结构化的JSON数据,适合灵活扩展字段。 | |
| Array | 数组类型,可以存储一组同类型的值。 |
- 主键字段:每个集合必须有一个主键,保证每条数据唯一。可以用数字(INT64)或字符串(VARCHAR)。
- 向量字段:用于存储AI模型生成的特征向量,是Milvus支持“相似度检索”的核心。
- 例如:图片特征用Float Vector,文本检索用BM25(Varchar)。
- 标量字段:存储普通属性,如年龄(Int32)、价格(Float)、标签(VarChar)、扩展信息(JSON)等。
5.2 分词匹配 #
Standard分词器是最基本的分词方式,它按照一定规则把文本切分成词语,这样在搜索时就能更准确地找到包含特定词语的内容。
5.2.2 启用匹配 #
让集合支持基于这些词条的匹配与相似度检索,例如你输入“电脑”,系统会在已经分词的词条里查找“计算机”“笔记本”等相关词。 这就像是你在搜索引擎中输入关键词,即使不是完全一样的词,也能找到相关内容。
5.2.3 分区键 #
分区键用来将大量数据分散存储在不同的服务器上。
比如我们班里想把同学们进行分组,分组的依据是同学们的姓氏,那么姓氏就是分区键
5.2.4.代码演示 #
# 导入默认字典,用于分区聚合
from collections import defaultdict
# 导入结巴分词工具
import jieba
# 定义示例文档数据,每个文档包含“id”、“分区键”、“内容”
documents = [
{"id": 1, "partition_key": "张", "content": "张三喜欢编程和电脑游戏"},
{"id": 2, "partition_key": "李", "content": "李四热爱计算机科学"},
{"id": 3, "partition_key": "王", "content": "王五喜欢阅读技术书籍"},
{"id": 4, "partition_key": "张", "content": "张杰钟爱笔记本电脑"},
]
# 定义同义词映射,“键”为代表词,“值”为同义词集合(用于扩展匹配)
synonym_map = {
"电脑": {"电脑", "计算机", "PC"},
"编程": {"编程", "程序设计"},
}
# 对输入文本进行分词(搜索模式),返回词元列表
def simple_tokenize(text: str):
"""说明:使用 jieba 搜索模式,得到更细粒度的词元"""
return [token for token in jieba.lcut_for_search(text) if token.strip()]
# 根据“分区键”对文档进行聚合,返回分区字典
def build_partitions(docs):
"""说明:按照分区键将文档聚合"""
partitions = defaultdict(list)
for doc in docs:
partitions[doc["partition_key"]].append(doc)
return partitions
# 在所有分区内查找包含指定关键词(或同义词)的文档
def match_query(partitions, keyword: str, use_synonym=True):
"""说明:在指定分区内执行匹配,支持同义词扩展"""
# 构建本次要匹配的词集合,默认为仅包含keyword
tokens_to_match = {keyword}
# 如果启用同义词且keyword在同义词表中,则扩展为所有同义词
if use_synonym and keyword in synonym_map:
tokens_to_match = synonym_map[keyword]
# 结果列表,用于收集匹配文档
results = []
# 遍历每个分区和分区下的文档
for partition_key, docs in partitions.items():
for doc in docs:
# 对文档内容进行分词
tokens = simple_tokenize(doc["content"])
# 判断有无交集(有则说明匹配)
if tokens_to_match.intersection(tokens):
results.append((partition_key, doc["id"], doc["content"]))
# 返回所有匹配结果
return results
# 程序主入口
if __name__ == "__main__":
# 按分区键聚合文档
partitions = build_partitions(documents)
# 示例1:只匹配“电脑”本词
hits = match_query(partitions, keyword="电脑", use_synonym=False)
print("仅匹配“电脑”的结果:")
for row in hits:
print(row)
# 示例2:启用同义词匹配(“电脑”≈“计算机”)
hits_with_synonym = match_query(partitions, keyword="电脑", use_synonym=True)
print("\n启用同义词匹配后的结果:")
for row in hits_with_synonym:
print(row)5.3 Nullable #
Nullable表示这个字段可以为空。就像填表格时,有些项目是必填的(不能为空),有些是选填的(可以为空)。如果勾选了Nullable,就意味着这个字段可以不填写任何值。
5.4 一致性 (Bounded) #
在数据库或分布式系统中,“一致性”表示多个副本或节点上的数据保持同步、相同的程度。 Milvus支持的“Bounded(一致性有界)”是一种典型的弱一致性模型,它介于强一致性和最终一致性之间。通俗讲:不是所有副本立刻同步,但保证在“某个可控的时限”内,所有节点的数据最终都能达到一致。
5.4.1 选项 #
在Milvus数据库创建集合时,有四种一致性选项
5.4.1.1 Strong(强一致性) #
比如在班级里,当老师发布一条通知后,所有同学必须立即收到并确认,老师才会继续下一步。这种方式最可靠,但速度较慢,因为要等待每个人都确认。
5.4.1.2 Session(会话一致性) #
这像是你和好友的私聊。你发的消息,你的好友一定能按顺序收到,但其他同学可能暂时看不到或顺序不同。
5.4.1.3 Bounded(有界一致性) #
这像是黑板上写的通知。老师写完通知后,同学们会在一定时间内(比如10分钟)都能看到,但不要求立即。
5.4.1.4 Eventually(最终一致性) #
这像是口口相传的小道八卦消息。信息最终会传到每个人那里,但可能需要较长时间,且不保证具体何时。
5.4.2 代码演示 #
import random
import time
from typing import List, Dict
STUDENTS = ["小张", "小李", "小王", "小刘"]
def strong_consistency(message: str) -> None:
"""说明:强一致性——必须等所有人确认收到后,老师才算广播成功。"""
print("\n[Strong] 老师开始广播:", message)
for name in STUDENTS:
print(f" → {name} 收到并确认:{message}")
time.sleep(0.3) # 模拟等待确认
print("[Strong] 所有人都确认,老师继续下一步\n")
def session_consistency(message: str, session_owner: str) -> None:
"""说明:会话一致性——只保证当前会话(某个学生)看到自己的操作,其他同学稍后再同步。"""
print(f"\n[Session] {session_owner} 在私聊中提交:{message}")
print(f" → {session_owner} 立即看到自己发的内容")
print(" → 其他同学稍后通过公共同步获得,不保证时间顺序\n")
def bounded_consistency(message: str, bound_seconds: int = 5) -> None:
"""说明:有界一致性——在指定时间窗口内同步即可,不要求立刻。"""
print(f"\n[Bounded] 老师写在黑板上:{message}(需要在 {bound_seconds} 秒内传达到)")
reached: Dict[str, float] = {}
for name in STUDENTS:
delay = random.uniform(0, bound_seconds)
time.sleep(delay / 10) # 缩短真实等待,方便演示
reached[name] = delay
print(f" → {name} 在 {delay:.2f} 秒后看到黑板信息")
print("[Bounded] 所有人都在规定时间内看到了通知\n")
def eventual_consistency(message: str) -> None:
"""说明:最终一致性——通知顺序与到达时间都不确定,但最终所有人会知道。"""
print("\n[Eventually] 消息通过口口相传传播:", message)
remaining = STUDENTS.copy()
random.shuffle(remaining)
total_delay = 0.0
while remaining:
name = remaining.pop()
delay = random.uniform(0.5, 2.0)
total_delay += delay
time.sleep(delay / 10) # 缩短等待
print(f" → {name} 在约 {total_delay:.1f} 秒后才听到消息")
print("[Eventually] 虽然有延迟,但最终每个人都掌握了消息\n")
if __name__ == "__main__":
strong_consistency("今晚 8 点线上作业答疑")
session_consistency("我提交了一次向量插入操作", session_owner="小李")
bounded_consistency("10 分钟内完成实验截图上交", bound_seconds=10)
eventual_consistency("下周可能有一次临时测验,注意关注群通知")- Strong:每次广播都等待所有人确认,最可靠但最慢;
- Session:保证某个“会话拥有者”能立即看到自己提交的内容,其他人稍后同步;
- Bounded:只需在规定时间窗口内达到即可;
- Eventually:到达顺序和时间不可控,但最终所有人都会收到。
5.4.5 如何选择? #
- 需要数据绝对准确时(如银行交易)→ 选Strong
- 需要用户看到自己操作的结果时 → 选Session
- 需要在一定时间内保证一致性 → 选Bounded
- 对时间要求不高,但希望系统运行更快 → 选Eventually
6. schema #
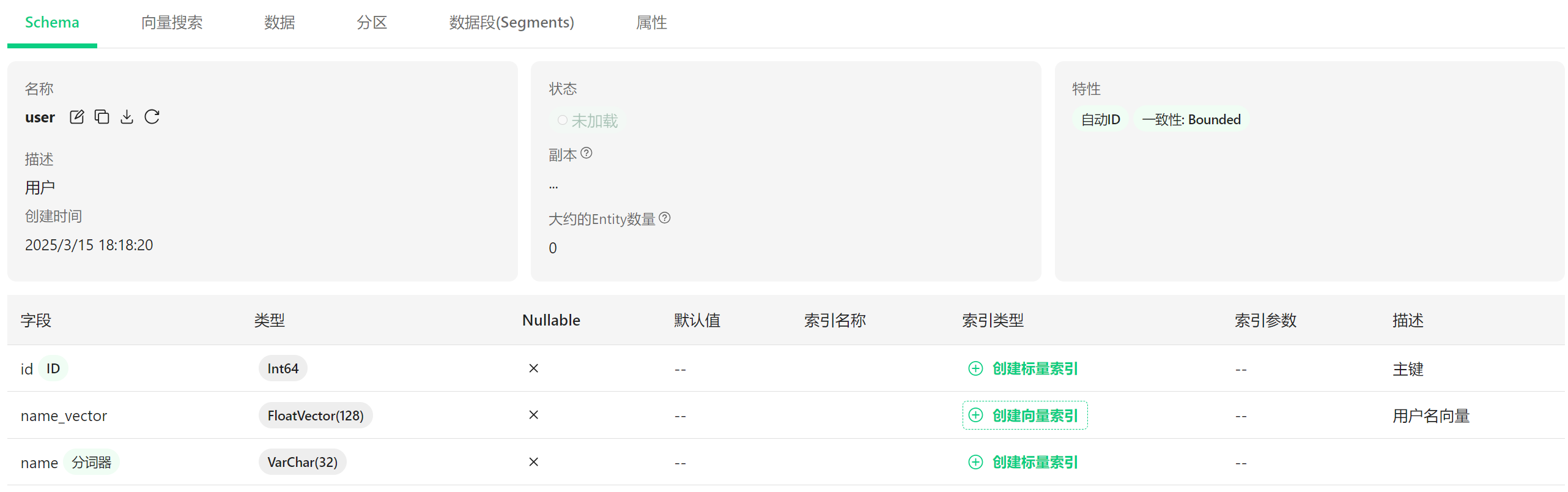
6.1 界面 #
集合基本信息
- 名称:user(用户)
- 描述:用户
- 创建时间:2023年3月15日 18:18:20
- 状态:未加载(表示数据还没有加载到内存中)
- 副本:1
- 大约的Entity数量:0(表示集合中还没有数据)
集合特性
- 自动ID:已启用(系统会自动生成ID)
- 一致性:Bounded(有界一致性,这是数据一致性的一种模式)
字段信息 集合包含三个字段:
id
- 类型:Int64(64位整数)
- 不可为空(Nullable: ×)
- 是主键(ID)
- 可以创建标量索引
name_vector
- 类型:FloatVector(128)(128维浮点向量)
- 不可为空
- 可以创建向量索引
- 描述:用户名向量
name
- 类型:VarChar(32)(最多32个字符的可变长度字符串)
- 不可为空
- 使用分词器
- 可以创建标量索引
6.2 副本 #
副本(Replica)就像是你重要笔记的复印件。想象一下,如果你有一本非常重要的笔记本:
- 你可能会担心笔记本丢失
- 你可能希望多个同学同时查看笔记内容
- 你可能想防止笔记本被意外损坏
所以,你决定复印几份一模一样的副本。在Milvus中,副本就是数据的完整拷贝。
副本的作用
- 提高可靠性:如果一个数据副本损坏或丢失,系统可以使用其他副本继续工作
- 提高查询性能:多个副本可以同时处理不同的查询请求,就像多个同学可以同时看不同的笔记副本
- 负载均衡:查询请求可以分散到不同的副本上,避免单个服务器压力过大
6.3 状态 #
在Milvus中,必须先加载(load)集合到内存,才能创建和使用索引
6.3.1 为什么需要加载集合? #
Milvus采用了内存计算的架构:
- 数据存储在磁盘上
- 但搜索、索引等操作需要在内存中进行
- 加载操作就是将集合数据从磁盘读入内存
6.3.2 Milvus集合生命周期管理 #
在Milvus中,集合有几种状态:
已创建但未加载:
- 集合存在于磁盘上
- 不能进行搜索或索引操作
- 占用最少资源
已加载:
- 集合数据在内存中
- 可以进行所有操作(搜索、索引等)
- 占用内存资源
已释放:
- 集合数据从内存中释放
- 回到"未加载"状态
- 释放内存资源
- 加载前请保证所有向量列都有索引
7. 创建索引 #
7.1 什么是索引? #
想象一下,索引就像是一本书的目录。如果没有目录,你想找某个内容就必须从头到尾翻阅整本书。 有了目录,你可以快速找到你想要的内容在哪一页。
在数据库中,索引也是这样工作的,它帮助计算机快速找到你要的数据。
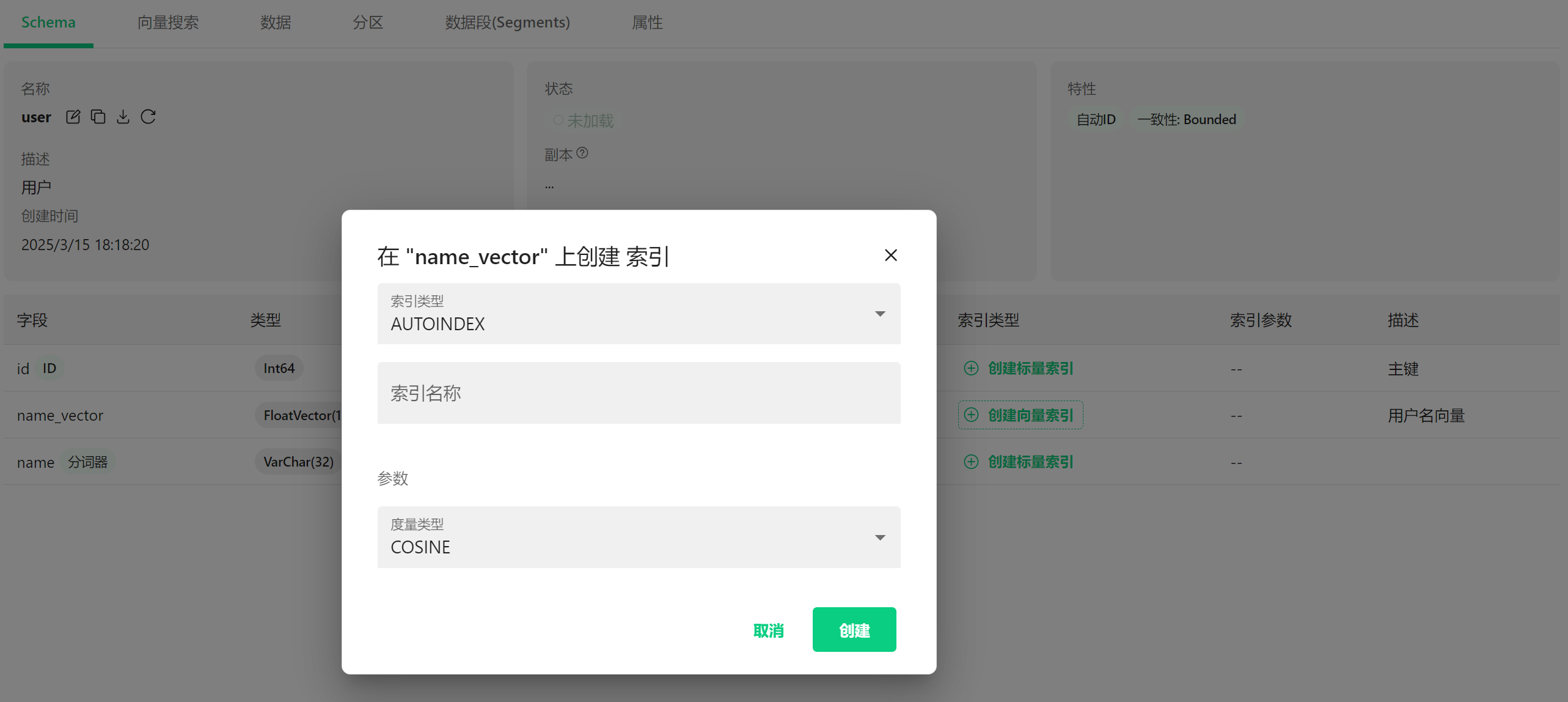
7.2 索引创建界面 #
这个弹窗显示我们正在为"name_vector"字段(也就是用户名的向量表示)创建索引:
索引类型:AUTOINDEX
- 这是一种自动选择最适合的索引类型的方式
- Milvus会根据你的数据特点自动选择最合适的索引结构
索引名称:
- 这里可以输入索引的名字
参数设置:
- 度量类型:COSINE(余弦相似度)
- 这决定了如何计算两个向量之间的"距离"或"相似度"
7.3 度量类型 #
# 导入math模块用于数学运算
import math
# 从typing模块导入List和Sequence用于类型注解
from typing import List, Sequence
# 定义函数,计算两个向量的欧几里得距离
def l2_distance(vec_a: Sequence[float], vec_b: Sequence[float]) -> float:
# 说明:计算欧几里得距离
# 判断两个向量的长度是否相等
if len(vec_a) != len(vec_b):
# 如果长度不等,抛出异常
raise ValueError("向量维度必须一致")
# 计算每个对应元素之差的平方和,再开平方根
return math.sqrt(sum((a - b) ** 2 for a, b in zip(vec_a, vec_b)))
# 定义函数,计算两个向量的内积
def inner_product(vec_a: Sequence[float], vec_b: Sequence[float]) -> float:
# 说明:计算向量内积
# 判断两个向量的长度是否相等
if len(vec_a) != len(vec_b):
# 如果长度不等,抛出异常
raise ValueError("向量维度必须一致")
# 返回对应位置元素相乘后的和
return sum(a * b for a, b in zip(vec_a, vec_b))
# 定义函数,计算两个向量的余弦相似度
def cosine_similarity(vec_a: Sequence[float], vec_b: Sequence[float]) -> float:
# 说明:计算余弦相似度
# 计算内积
dot = inner_product(vec_a, vec_b)
# 计算第一个向量的模长
norm_a = math.sqrt(sum(a * a for a in vec_a))
# 计算第二个向量的模长
norm_b = math.sqrt(sum(b * b for b in vec_b))
# 判断模长是否为0,避免除以0
if norm_a == 0 or norm_b == 0:
# 如果模长为0,抛出异常
raise ValueError("向量模长不能为 0")
# 返回内积除以模长乘积的结果
return dot / (norm_a * norm_b)
# 定义函数,计算两个向量的汉明距离(适用于二进制或等长序列)
def hamming_distance(vec_a: Sequence[int], vec_b: Sequence[int]) -> int:
# 说明:计算汉明距离(适用于二进制或等长序列)
# 判断两个向量长度是否一致
if len(vec_a) != len(vec_b):
# 如果长度不等,抛出异常
raise ValueError("向量长度必须一致")
# 统计对应位置元素不相等的数量
return sum(1 for a, b in zip(vec_a, vec_b) if a != b)
# 程序主入口
if __name__ == "__main__":
# 定义两个float类型的向量
vec1: List[float] = [1, 2, 3]
vec2: List[float] = [4, 5, 6]
# 定义两个int类型的向量,用于汉明距离
bin1: List[int] = [1, 0, 1, 0, 1]
bin2: List[int] = [1, 1, 0, 0, 0]
# 打印L2距离,保留两位小数
print("L2 距离:", format(l2_distance(vec1, vec2), ".2f"))
# 打印向量内积,保留两位小数
print("内积:", format(inner_product(vec1, vec2), ".2f"))
# 打印余弦相似度,保留两位小数
print("余弦相似度:", format(cosine_similarity(vec1, vec2), ".2f"))
# 打印汉明距离
print("汉明距离:", hamming_distance(bin1, bin2))7.4 归一化 #
# 导入math模块用于数学计算
import math
# 从typing模块导入List和Sequence类型用于类型标注
from typing import List, Sequence
# 定义归一化函数,将向量的长度缩放为1,方向保持不变
def normalize(vector: Sequence[float]) -> List[float]:
# 计算向量模长(欧氏范数)
norm = math.sqrt(sum(component * component for component in vector))
# 如果模长为0,抛出异常,无法归一化零向量
if norm == 0:
raise ValueError("零向量无法归一化,因为长度为 0")
# 返回归一化后的向量(每个分量除以向量模长)
return [component / norm for component in vector]
# 主程序入口
if __name__ == "__main__":
# 定义一个二维向量
vec = [3.0, 4.0]
# 调用normalize函数对向量归一化
normalized_vec = normalize(vec)
# 输出原始向量
print(f"原向量:{vec}")
# 输出归一化后的向量
print(f"归一化结果:{normalized_vec}")
# 计算归一化后向量的长度(再次验证是否为1)
length = math.sqrt(sum(x * x for x in normalized_vec))
# 输出归一化后向量的长度,保留两位小数
print(f"归一化后长度:{length:.2f}")7.5 加载集合 #
创建完索引后,需要加载集合才能使用索引进行搜索。
8. 加载数据 #
- 导入文件:从文件中导入数据
- 插入样本数据:添加示例数据
- 清空数据:删除所有数据
9. 向量搜索 #
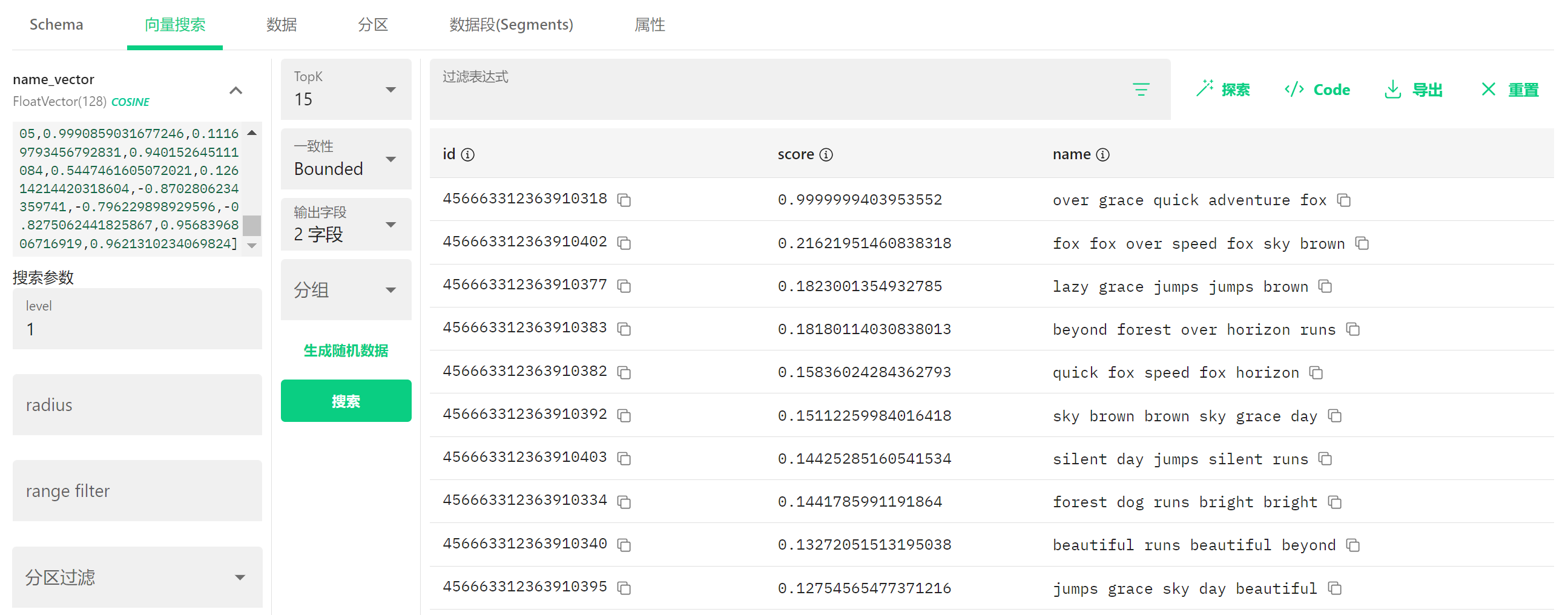
9.1 什么是向量搜索? #
向量搜索就像是在说:"给我找一些和这个例子很像的东西!" 在这个例子中,我们是在寻找与某个输入向量相似的用户名。
9.2 界面左侧(搜索条件) #
搜索向量:
- 顶部显示了一个向量:[0.9990859031677246, 0.1116979345679283, ...]
- 这是我们要查找相似内容的"样本"
搜索参数:
- TopK:15(表示要返回最相似的15条结果)
- 一致性:Bounded(搜索的一致性模式)
- 输出字段:2个字段(选择显示哪些字段)
- 分组:(未选择)
- 搜索参数:
- level:1(搜索精度级别)
- radius:(未设置)
- range filter:(未设置)
- 分区过滤:(未设置)
9.3 界面右侧(搜索结果) #
搜索结果显示了与输入向量最相似的用户名,按相似度(score)从高到低排序:
第一行:
- id: 456663312363910318
- score: 0.9999999403953552(几乎完全匹配!)
- name: over grace quick adventure fox
第二行:
- id: 456663312363910402
- score: 0.2162195146083818
- name: fox fox over speed fox sky brown
第三行:
- id: 456663312363910377
- score: 0.1823001354932785
- name: lazy grace jumps jumps brown
...以此类推,显示了更多结果。
9.4 搜索参数 #
9.4.1 Level(搜索精度级别) #
Level参数是控制搜索精度和速度平衡的关键:
什么是Level?
- Level是一个整数值,通常从1到100
- 现在设置为1
Level的作用:
- 低Level值(如1-2):搜索速度快,但可能会漏掉一些相似结果
- 高Level值(如50-100):搜索更精确,找到更多相似结果,但速度较慢
生活中的例子: 想象你在找一本书。Level=1就像快速扫一眼书架,只看书脊;Level=100就像仔细检查每本书的内容。
9.4.2 Radius(搜索半径) #
Radius参数定义了在向量空间中搜索的范围:
什么是Radius?
- 它是一个浮点数,表示向量空间中的距离
Radius的作用:
- 只返回与查询向量距离小于radius的结果
- 即使设置了TopK=15,如果只有3个结果在radius范围内,也只会返回这3个结果
生活中的例子: 想象你站在一个点,说"我只想知道5公里范围内的所有餐厅",这里的"5公里"就是radius。
9.4.3 Range Filter(范围过滤器) #
Range Filter参数允许我们根据向量距离进行更精细的过滤:
什么是Range Filter?
- 它是一个表达式,定义了接受结果的距离范围
Range Filter的作用:
- 可以设置最小和最大距离
- 例如:"distance >= 0.5 && distance <= 0.9"
- 这会只返回距离在0.5到0.9之间的结果
生活中的例子: 想象你在找房子,说"我想要离学校不少于500米(避免噪音),但不超过2公里(方便接送)的房子"。
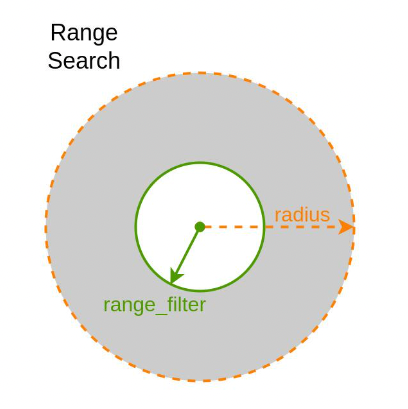
Range Search 新增了 2 个参数,分别是:
- radius(半径) - 指相似性的外边界
- range_filter(范围过滤器) - 指相似性的内边界
9.4.4 代码演示 #
# 导入math模块用于数学运算
import math
# 导入类型注解List, Tuple
from typing import List, Tuple
# 生成20个“数据库向量”,每个向量包含id和二维向量tuple
DATABASE = [
{"id": i, "vector": (i * 0.1, i * 0.1 + 0.3)}
for i in range(20)
]
# 定义欧几里得距离函数,计算两个二维向量之间的距离
def l2_distance(a: Tuple[float, float], b: Tuple[float, float]) -> float:
# 对输入的两个向量a和b,依次计算同一维度差的平方,并求和后开方
return math.sqrt(sum((x - y) ** 2 for x, y in zip(a, b)))
# 根据level参数粗略或深入地搜索向量,level越高候选越多
def search_with_level(query: Tuple[float, float], level: int) -> List[int]:
"""
说明:
- Level 越低,只粗略检查少量候选;
- Level 越高,深入检查更多候选,结果更全。
"""
# 按与query向量的距离升序排序所有数据库向量
sorted_vectors = sorted(DATABASE, key=lambda item: l2_distance(query, item["vector"]))
# 根据level确定需要检查的比例,level范围映射到0.1~1.0
ratio = max(0.1, min(level / 100, 1.0))
# 计算需要返回的候选数量,至少为1个
top_k = max(1, int(len(sorted_vectors) * ratio))
# 返回前top_k个向量的id
return [item["id"] for item in sorted_vectors[:top_k]]
# 根据半径参数radius查找与query距离不超过radius的向量
def search_with_radius(query: Tuple[float, float], radius: float) -> List[int]:
"""
说明:只返回与 query 距离 <= radius 的向量
"""
# 保存符合条件的向量id
result = []
# 遍历数据库中的所有向量
for item in DATABASE:
# 判断与query的距离是否小于等于radius
if l2_distance(query, item["vector"]) <= radius:
# 满足条件则添加id到结果中
result.append(item["id"])
# 返回所有符合条件的id
return result
# 根据指定的距离区间筛选与query之间距离在范围内的向量
def search_with_range_filter(
query: Tuple[float, float],
min_distance: float,
max_distance: float
) -> List[int]:
"""
说明:仅保留 min_distance <= distance <= max_distance 的向量
"""
# 保存查询结果
result = []
# 遍历所有数据库向量
for item in DATABASE:
# 计算query与当前向量的距离
d = l2_distance(query, item["vector"])
# 如果距离在指定区间则将其id加入结果
if min_distance <= d <= max_distance:
result.append(item["id"])
# 返回所有符合区间条件的id
return result
# 主程序入口
if __name__ == "__main__":
# 定义查询向量
query_vector = (0.5, 0.8)
# 输出level为10(粗略)的搜索结果
print("Level=10(粗略):", search_with_level(query_vector, level=10))
# 输出level为70(深入)的搜索结果
print("Level=70(深入):", search_with_level(query_vector, level=70))
# 输出radius为0.5的搜索结果
print("Radius=0.5:", search_with_radius(query_vector, radius=0.5))
# 输出radius为1.2的搜索结果
print("Radius=1.2:", search_with_radius(query_vector, radius=1.2))
# 输出距离在0.4到0.9之间的向量id
print("Range Filter: 0.4 <= d <= 0.9 ->",
search_with_range_filter(query_vector, min_distance=0.4, max_distance=0.9))9.4.4 分区过滤 #
Milvus中的"分区过滤"功能是向量搜索中另一个非常重要的参数,它可以帮助我们更高效地组织和搜索数据。

10. 数据段 #

10.1 什么是数据段? #
数据段就像是数据库中存储数据的小容器。想象一下,如果数据库是一个图书馆,分区就是不同的书架区域,而数据段则是书架上的具体书籍盒子,里面装着实际的数据。
功能按钮:
- "压缩(Compact)":可以压缩数据段,让它占用更少空间
- "落盘(Flush)":把内存中的数据写入到硬盘上保存
- "刷新":更新显示最新的数据段信息
数据段信息:
- ID:456663312364110319(这是数据段的唯一标识符)
- Level:L1(这表示数据段的层级)
- 分区ID:456663312362905661(这个数据段属于哪个分区)
- 持久数据段状态:Flushed(表示数据已经保存到硬盘上)
- 行数:100(这个数据段包含100行数据)
- 查询节点IDs:1(表示哪些节点可以查询这个数据段)
- 查询数据段状态:Sealed(表示这个数据段已经封闭,不能再添加新数据)
10.2 什么是查询节点ID #
查询节点ID是指在分布式数据库系统中,负责处理查询请求的服务器或计算单元的唯一标识符。
10.2.1 查询节点 #
想象一个大型图书馆,有很多工作人员(节点)分布在不同的楼层和区域:
- 每个工作人员都有自己的工号(节点ID)
- 每个工作人员负责管理特定书架上的图书(数据段)
- 当你需要查找一本书时,你的请求会被分配给负责那个区域的工作人员
10.2.2 含义 #
"查询节点IDs: 1" 表示:
- 这个数据段(ID为456663312364110319)目前被分配给了ID为1的查询节点
- 只有这一个节点(节点1)负责处理对这个数据段的查询请求
- 如果有人想查询这个数据段中的信息,请求会被路由到节点1处理
10.2.3 类比 #
这就像学校的分组学习:
- 每个小组有一个编号(节点ID)
- 每个小组负责研究特定的知识点(数据段)
- 当老师提问某个知识点时,相应的小组就负责回答(处理查询)
11. 属性 #
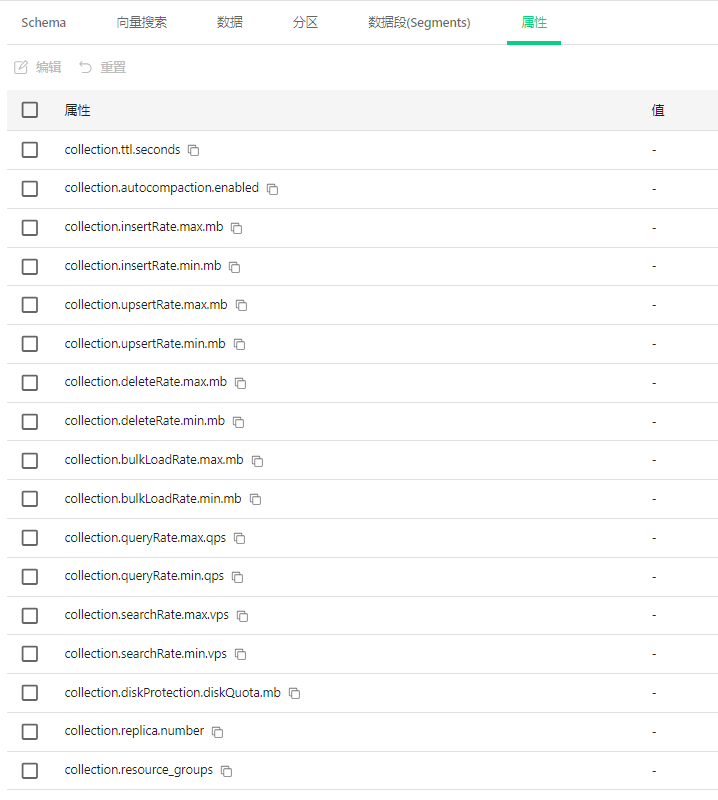
11.1 什么是集合属性? #
集合属性就像是对数据库的"规则设定",它们控制着数据库如何处理数据、多快处理数据,以及使用多少资源。
11.2 界面中的属性列表 #
属性都以"collection."开头,表示这些是针对当前集合的设置:
collection.ttl.seconds
- 这是"生存时间"设置,决定数据在集合中保存多长时间
- 如果设置了这个值,超过这个时间的数据会被自动删除
collection.autocompaction.enabled
- 控制是否启用自动压缩功能
- 压缩可以减少存储空间并提高查询效率
数据操作速率限制:
- collection.insertRate.max.mb 和 min.mb:插入数据的最大和最小速率
- collection.upsertRate.max.mb 和 min.mb:更新插入的最大和最小速率
- collection.deleteRate.max.mb 和 min.mb:删除数据的最大和最小速率
- collection.bulkLoadRate.max.mb 和 min.mb:批量加载的最大和最小速率
查询速率限制:
- collection.queryRate.max.qps 和 min.qps:普通查询的最大和最小每秒查询数
- collection.searchRate.max.qps 和 min.qps:向量搜索的最大和最小每秒查询数
资源管理:
- collection.diskProtection.diskQuota.mb:磁盘配额,限制集合可以使用的磁盘空间
- collection.replica.number:副本数量,用于数据备份和负载均衡
- collection.resource_groups:资源组设置,控制集合可以使用的计算资源
12. 操作milvus数据库 #
# Python 环境中安装 pymilvus
python3 -m pip install --upgrade pymilvus==2.6.312.1 连接数据库 #
# 导入pymilvus中的连接和工具包
from pymilvus import connections, utility
# 定义测试数据库连接的函数,包含主机host、端口port、数据库名db_name,设置默认值
def test_connection(
host: str = "127.0.0.1", port: str = "19530", db_name: str = "default"
) -> bool:
try:
# 建立到Milvus的连接
connections.connect("default", host=host, port=port, timeout=10, db_name=db_name)
# 打印当前连接到的数据库名称
print(f"当前连接到的数据库为: {db_name}")
# 获取所有集合名并打印
collections = utility.list_collections()
print(f"数据库 '{db_name}' 下的集合有:", collections)
# 连接成功提示
print("连接成功:已成功连接到 Milvus 服务器")
return True
except Exception as exc:
# 捕获连接失败异常并打印
print(f"连接失败:无法连接到 Milvus 服务器的数据库 '{db_name}' ->", exc)
return False
finally:
# 断开连接
connections.disconnect("default")
print("已关闭与 Milvus 服务器的连接")
# 主程序入口:调用连接测试
if __name__ == "__main__":
if not test_connection():
# 如果连接失败则程序退出
raise SystemExit(1)12.2 Schema管理 #
# 导入pymilvus相关类和函数
from pymilvus import (
connections,
db,
FieldSchema,
CollectionSchema,
DataType,
Collection,
utility,
)
# 创建一个新的articles集合(表)
def create_articles_collection(
db_name: str = "blog",
collection_name: str = "articles",
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否已存在
if utility.has_collection(collection_name):
print(f"集合 {collection_name} 已存在")
return
# 定义id字段,类型为长整型,主键且非自增
id_field = FieldSchema(
name="id",
dtype=DataType.INT64,
is_primary=True,
auto_id=False,
description="文章 ID",
)
# 定义title字段,类型为变长字符串
title_field = FieldSchema(
name="title",
dtype=DataType.VARCHAR,
max_length=512,
description="文章标题",
)
# 定义title_vector字段,类型为3维浮点向量
vector_field = FieldSchema(
name="title_vector",
dtype=DataType.FLOAT_VECTOR,
dim=3,
description="标题向量(示例为 3 维)",
)
# 创建集合schema
schema = CollectionSchema(
fields=[id_field, title_field, vector_field],
description="文章信息集合",
)
# 创建集合
Collection(name=collection_name, schema=schema, using="default")
print(f"集合 {collection_name} 创建成功")
# 打印当前所有集合名
print("当前集合列表:", utility.list_collections())
except Exception as exc:
# 捕获异常并打印
print("创建集合失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
# 主程序入口,创建articles集合
if __name__ == "__main__":
create_articles_collection()12.4 索引管理 #
# 导入pymilvus所需模块
from pymilvus import connections, db, utility, Collection
# 确保集合索引存在,如不存在则创建索引
def ensure_index(
db_name: str = "blog",
collection_name: str = "articles",
field_name: str = "title_vector",
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否存在
if not utility.has_collection(collection_name):
raise ValueError(f"集合 {collection_name} 不存在,无法创建索引")
# 获取集合对象
collection = Collection(collection_name)
# 判断是否已有索引
has_index = bool(collection.indexes)
if has_index:
print("索引已存在,跳过创建")
else:
# 定义索引参数(IVF_FLAT算法,L2距离,nlist=128)
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
# 创建索引
collection.create_index(field_name=field_name, index_params=index_params)
print("索引创建成功")
# 加载集合到内存
collection.load()
print("集合已加载到内存,可供查询")
except Exception as exc:
# 打印异常
print("索引管理失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
# 主程序入口,确保索引
if __name__ == "__main__":
ensure_index()12.5 集合管理 #
# 导入pymilvus相关模块
from pymilvus import connections, db, Collection, utility
# 查看集合信息,并根据需要在查看后删除集合
def inspect_collection(
db_name: str = "blog",
collection_name: str = "articles",
drop_after_inspect: bool = False,
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否存在
if not utility.has_collection(collection_name):
print(f"集合 {collection_name} 不存在,无法执行后续操作")
return
# 获取集合对象
collection = Collection(collection_name)
# 输出集合schema信息
print("集合信息:\n", collection.schema)
# 输出集合中的entity总数
print("集合统计:", collection.num_entities)
# 输出所有集合名称
print("所有集合:", utility.list_collections())
# 释放集合内存
collection.release()
print("集合已从内存释放")
# 判断是否需要删除集合
if drop_after_inspect:
utility.drop_collection(collection_name)
print("集合已删除")
except Exception as exc:
# 捕获异常并打印
print("操作失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
print("已关闭与 Milvus 服务器的连接")
# 主程序入口,查看并可选择删除集合
if __name__ == "__main__":
inspect_collection()12.6 数据管理 #
# 导入pymilvus相关内容
from pymilvus import connections, db, Collection, utility
# 数据增、改、删操作示例
def manage_data(
db_name: str = "blog",
collection_name: str = "articles",
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否存在
if not utility.has_collection(collection_name):
print("集合不存在,无法执行数据操作")
return
# 获取集合对象
collection = Collection(collection_name)
# 插入数据,分三列:id, title, title_vector
insert_result = collection.insert(
[
[1, 2],
["中国", "伟大"],
[[0.1, 0.2, 0.3], [0.4, 0.5, 0.6]],
]
)
print("插入数据成功:", insert_result.insert_count)
# 以upsert形式插入新数据、更新已存在数据
upsert_result = collection.upsert(
[
[1, 2, 3],
["中国2", "伟大2", "祖国"],
[[0.2, 0.4, 0.6], [0.8, 1.0, 1.2], [0.7, 0.8, 0.9]],
]
)
print("Upsert 数据成功:", upsert_result.insert_count)
# 删除数据,按表达式条件
delete_result = collection.delete(expr="id in [1,2]")
print("删除数据成功:", delete_result.delete_count)
except Exception as exc:
# 打印异常
print("操作失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
print("已关闭与 Milvus 服务器的连接")
# 主程序入口,进行数据管理操作
if __name__ == "__main__":
manage_data()12.7 搜索 #
# 导入pymilvus相关模块
from pymilvus import connections, db, Collection, utility
# 简单的向量搜索函数
def simple_search(
db_name: str = "blog",
collection_name: str = "articles",
field_name: str = "title_vector",
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否存在
if not utility.has_collection(collection_name):
print("集合不存在,无法执行搜索")
return
# 获取集合对象
collection = Collection(collection_name)
# 加载集合到内存
collection.load()
# 执行向量检索,输入向量为[0.7, 0.8, 0.9]
search_result = collection.search(
data=[[0.7, 0.8, 0.9]],
anns_field=field_name,
param={"metric_type": "L2", "params": {"nprobe": 10}},
limit=10,
output_fields=["title"],
)
# 遍历结果,逐条打印id、距离和title
for hits in search_result:
for hit in hits:
print(f"id={hit.id}, distance={hit.distance:.4f}, title={hit.entity.get('title')}")
except Exception as exc:
# 捕获异常并打印
print("搜索失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
print("已关闭与 Milvus 服务器的连接")
# 主程序入口,执行简单搜索
if __name__ == "__main__":
simple_search()12.8 获取文本的向量嵌入 #
# 导入所需模块
import json
import os
import requests
# 获取API Token(从环境变量或默认字符串)
API_TOKEN = os.getenv("SILICONFLOW_TOKEN", "YOUR_TOKEN_HERE")
# 向量API地址
EMBED_URL = "https://api.siliconflow.cn/v1/embeddings"
# 向量模型名称
MODEL_NAME = "BAAI/bge-large-zh-v1.5"
# 获取文本对应的向量嵌入
def get_text_embedding(text: str) -> list[float]:
# 组装请求体
payload = {
"model": MODEL_NAME,
"input": text,
"encoding_format": "float",
}
# 组装Header(携带API Token)
headers = {
"Authorization": f"Bearer {API_TOKEN}",
"Content-Type": "application/json",
}
# 发送POST请求获取嵌入
resp = requests.post(EMBED_URL, json=payload, headers=headers, timeout=30)
# 检查响应状态
resp.raise_for_status()
# 返回第一个文本的embedding向量
return resp.json()["data"][0]["embedding"]
# 主程序入口:获取"张三"的向量并保存
if __name__ == "__main__":
embedding = get_text_embedding("张三")
# 保存到embedding.json
with open("embedding.json", "w", encoding="utf-8") as f:
json.dump(embedding, f)
print("向量嵌入已保存至 embedding.json")12.9 保存数据到milvus #
# 导入必要库
import os
import requests
from pymilvus import connections, db, Collection, utility
# 获取API Token(从环境变量)
API_TOKEN = os.getenv("SILICONFLOW_TOKEN", "sk-wtplxfsozuyrjsmlclpxivoogwwlkfyzrgcgsrfqfpymwnwb")
# 嵌入API地址
EMBED_URL = "https://api.siliconflow.cn/v1/embeddings"
# 嵌入模型名称
MODEL_NAME = "BAAI/bge-large-zh-v1.5"
# 获取单条文本的向量嵌入
def get_text_embedding(text: str) -> list[float]:
payload = {"model": MODEL_NAME, "input": text, "encoding_format": "float"}
headers = {"Authorization": f"Bearer {API_TOKEN}", "Content-Type": "application/json"}
resp = requests.post(EMBED_URL, json=payload, headers=headers, timeout=30)
resp.raise_for_status()
return resp.json()["data"][0]["embedding"]
# 示例:保存名字和对应向量到Milvus,并进行检索
def save_and_search_names(
db_name: str = "blog",
collection_name: str = "user",
field_name: str = "name_vector",
) -> None:
# 建立连接
connections.connect("default", host="127.0.0.1", port="19530")
try:
# 切换数据库
db.using_database(db_name)
# 检查集合是否存在
if not utility.has_collection(collection_name):
print("集合不存在,无法执行数据操作")
return
# 获取集合对象
collection = Collection(collection_name)
# 查找集合里指定的向量字段
vector_field = next(
(field for field in collection.schema.fields if field.name == field_name),
None,
)
if vector_field is None:
raise ValueError(f"集合中不存在字段 {field_name}")
# 获取字段定义的维度(如果有)
expected_dim = vector_field.params.get("dim") if hasattr(vector_field, "params") else None
# 示例名称
names = ["中国", "伟大"]
# 获取每个名字的嵌入向量
embeddings = [get_text_embedding(name) for name in names]
# 检查维度是否一致
if expected_dim and len(embeddings[0]) != expected_dim:
raise ValueError(
f"集合 {collection_name} 的向量维度为 {expected_dim},"
f"但当前模型输出维度为 {len(embeddings[0])},请保持一致。"
)
# 插入向量和名称
insert_result = collection.insert([embeddings, names])
# 将数据写入持久化
collection.flush()
# 加载集合到内存
collection.load()
print("数据插入成功:", insert_result.insert_count)
# 查询"华夏"的向量嵌入
query_vector = get_text_embedding("华夏")
# 执行向量检索
search_result = collection.search(
data=[query_vector],
anns_field=field_name,
param={"metric_type": "COSINE", "params": {"nprobe": 8}},
limit=5,
output_fields=["name"],
)
# 打印搜索结果
for hits in search_result:
for hit in hits:
print(f"匹配结果 name={hit.entity.get('name')}, score={hit.distance:.4f}")
except Exception as exc:
print("操作失败:", exc)
raise
finally:
# 断开连接
connections.disconnect("default")
print("已关闭与 Milvus 服务器的连接")
# 主程序入口:保存并检索名字
if __name__ == "__main__":
save_and_search_names()12.10 图片向量 #
# 导入所需模块
import base64
import requests
# 定义图片文件路径
image_path = "deepseek.png"
# 读取图片内容并进行base64编码
with open(image_path, "rb") as f:
base64_bytes = base64.b64encode(f.read())
base64_image = base64_bytes.decode('utf-8')
# 定义图片格式
image_format = "png"
# 拼接base64图片数据并加上MIME类型
image_data = f"data:image/{image_format};base64,{base64_image}"
# 定义API相关信息
api_url = 'https://dashscope.aliyuncs.com/api/v1/services/embeddings/multimodal-embedding/multimodal-embedding'
api_key = 'sk-dfa3b183ad004246947735edbfba7f2d'
# 调用多模态模型获取图片向量嵌入
def call_multi_modal_embedding():
# 设置HTTP请求头
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
# 构建请求体,包含模型名称和图片内容
payload = {
"model": "multimodal-embedding-v1",
"input": {
"contents": [
{
"image": image_data
}
]
}
}
try:
# 发送POST请求
response = requests.post(api_url, headers=headers, json=payload, timeout=30)
if response.status_code == 200:
# 解析并打印输出(格式化为JSON字符串)
output = response.json().get("output", {})
import json
print(json.dumps(output, ensure_ascii=False, indent=4))
else:
# 若请求失败打印状态码和错误内容
print("请求失败,状态码:", response.status_code)
print("响应内容:", response.text)
except Exception as e:
# 捕获接口调用异常
print("调用模型接口失败:", e)
# 主程序入口,调用多模态嵌入
if __name__ == "__main__":
call_multi_modal_embedding()13.APIKEY #
13.1 配置官方API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://api.deepseek.com |
| Deepseek:Apikey | sk-c50d5356a45c4c7988b3df82fb1295e3 |
| DeepseekModel | deepseek-chat 或者 deepseek-reasoner |
13.2 配置本地部署的DeepSeek R1 #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | http://localhost:11434 |
| DeepseekModel | deepseek-r1:1.5b |
13.3 配置硅基流动的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://api.siliconflow.cn |
| Deepseek:Apikey | sk-kgahvlalrbfjyftxrcoiiliopeblhxsgrxtrrwgiqwwxwxth |
| DeepseekModel | deepseek-ai/DeepSeek-V3或者deepseek-ai/DeepSeek-R1 |
13.4 配置派欧算力云的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://api.ppinfra.com/v3/openai |
| Deepseek:Apikey | sk_ASPYijn-VdsIbkEXtjCFNn0dEkvs6Sko6ZEA4XbWc |
| DeepseekModel | deepseek/deepseek-v3/community或者deepseek/deepseek-r1/community |
13.5 配置腾讯云的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://api.lkeap.cloud.tencent.com/v1 |
| Deepseek:Apikey | sk-EsdQJe0M4IsohNh4k0zji0bq9fsDDMQ77dmtn2hOMocTJCfj |
| DeepseekModel | deepseek-v3或者deepseek-r1 |
13.6 配置百度云的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://qianfan.baidubce.com/v2 |
| Deepseek:Apikey | bce-v3/ALTAK-VrJzzPHo9HRCH6Lq88QK8/6e9b1f33909b5a43dac2be242351006d72b |
| DeepseekModel | deepseek-v3或者deepseek-r1 |
13.7 配置阿里云的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://dashscope.aliyuncs.com/compatible-mode/v1 |
| Deepseek:Apikey | sk-cc2054c29cf54fec92503bf7044cf383 |
| DeepseekModel | deepseek-v3或者deepseek-r1 |
13.8 配置字节跳动火山引擎的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://ark.cn-beijing.volces.com/api/v3 |
| Deepseek:Apikey | d52e49a1-36ea-55bb-bc6e-65ce789a72f6 |
| DeepseekModel | deepseek-v3-241226或者deepseek-r1 |
13.9 配置科大讯飞的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://maas-api.cn-huabei-1.xf-yun.com/v1 |
| Deepseek:Apikey | sk-U9gPYdkeXmPoJWM33A168717c07544fEc983fF83b884e3785 |
| DeepseekModel | xdeepseekv3 |
13.10 配置openrouter的API Key #
| 配置项 | 值 |
|---|---|
| DeepSeek:baseUrl | https://openrouter.ai/api/v1 |
| Deepseek:Apikey | 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 |
| DeepseekModel | deepseek/deepseek-chat:free |
14.参考 #
- milvus
- milvus文档
- 度量类型
- 余弦相似度
- 归一化
- milvus安装
- milvus使用
- milvus管理数据库
- Level
- Radius
- range_filter
- 分区
- 查询节点ID
- 数据段
- 向量模型
- 创建嵌入请求
- 多模态模型
- 多模态模型apikey
- milvus安装文档
15.云服务器安装 #
wget https://gitee.com/milvus-io/milvus/raw/v2.6.4/deployments/docker/standalone/docker-compose.yml -O docker-compose.yml
docker compose up -d
docker run -p 8000:3000 -e MILVUS_URL=192.168.2.106:19530 zilliz/attu:v2.5