1. RAG系统评估 #
在AI产品开发过程中,通常会先实现一个基础版本(baseline),随后根据实际测试和反馈不断迭代优化。对于RAG(Retrieval-Augmented Generation)系统而言,科学的评估机制不仅是衡量系统优劣的关键,更是后续改进和升级的方向指引。因此,如何系统性地评估RAG模型的表现,成为项目落地过程中的核心环节。
2. RAG 系统评估的核心维度与方法 #
在本节中,我们将探讨如何科学地评判一个基于检索增强生成(RAG, Retrieval-Augmented Generation)系统的表现。
首先,简要回顾一下 RAG 的基本流程:用户提出问题,系统检索相关资料作为参考,然后大语言模型结合这些资料生成最终答案。
整个过程可以抽象为“提问—检索—生成”三步走。
RAG 的评估,正是围绕这三者之间的内在联系展开。
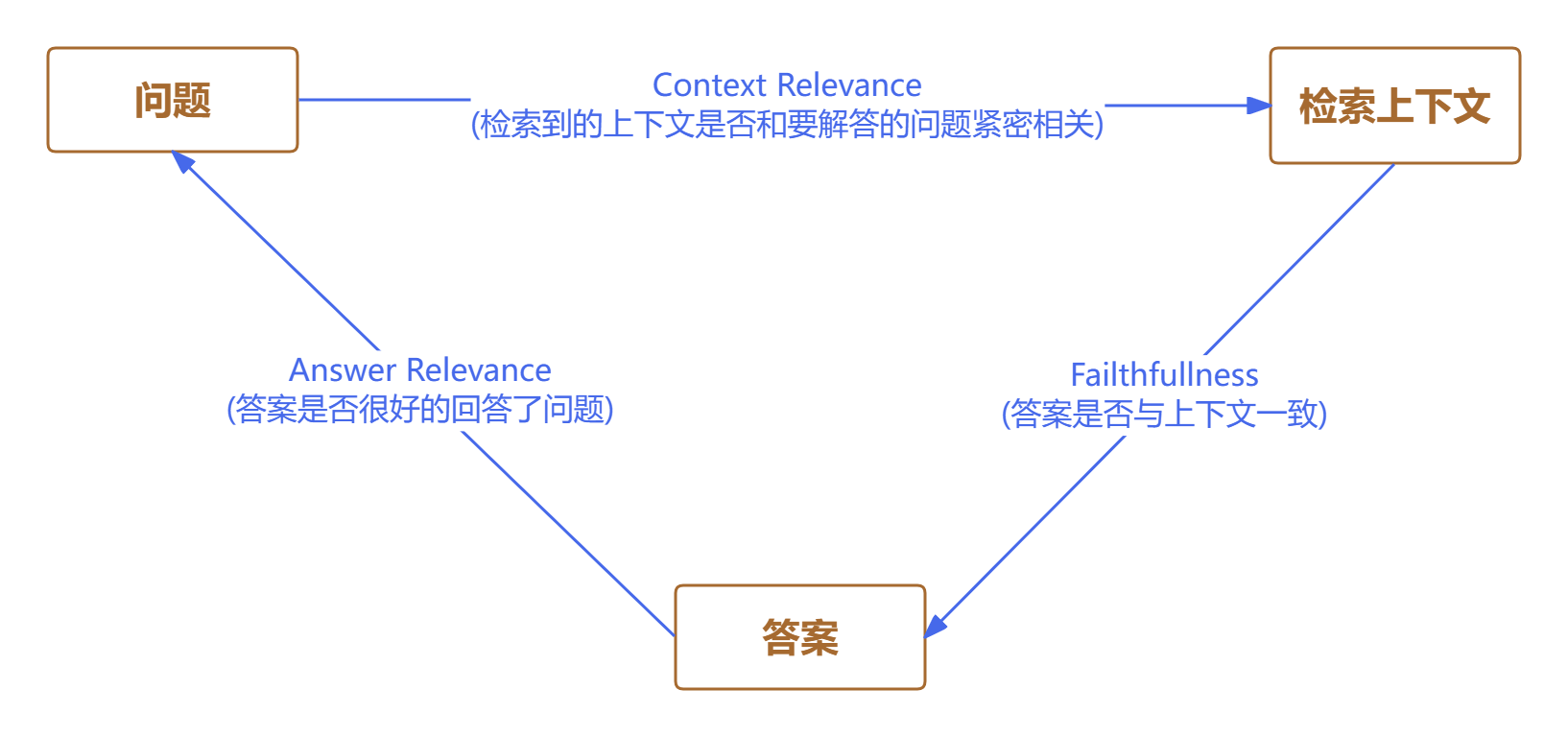
2.1. Context Relevance(检索内容的相关性) #
首先要考察的是,系统检索到的参考资料是否真正贴合用户的问题。
理想情况下,检索结果应当紧密围绕提问展开,涵盖解答所需的关键信息。
例如,假如用户询问“如何预防高血压?”,系统检索到的内容应包括饮食、运动等预防措施,而不是泛泛而谈的健康常识。
这个维度主要衡量检索内容的针对性和实用性。
2.2. Failthfullness(生成答案的事实一致性) #
其次,需要评估生成的答案是否忠实于检索到的资料。
换句话说,答案中的事实是否能够在参考资料中找到依据,避免凭空捏造。
例如,若检索内容提到“高血压患者应减少盐分摄入”,而生成的答案却建议“多吃甜食”,这就属于事实不一致。
事实一致性是确保系统输出可靠性的关键标准。
2.3. Answer Relevance(答案与问题的直接相关性) #
最后,还要判断生成的答案是否直接回应了用户的问题,并且内容是否完整、无遗漏。与此同时,还要避免答案中夹杂无关或冗余的信息。
例如,用户问“高血压的常见症状有哪些?”,理想答案应列举具体症状,而不是展开高血压的成因或治疗方法。这个维度关注答案的针对性和精炼度。
2.4 案例分析 #
| 项目 | 内容 | 检索相关性分析 | 答案与问题相关性分析 | 生成答案的事实一致性 |
|---|---|---|---|---|
| 用户问题 | 请简述地球自转的影响。 | —— | —— | —— |
| 资料A | 地球自转导致昼夜交替,并影响全球风系分布。 | 与问题高度相关 | —— | —— |
| 资料B | 太阳系中有八大行星,地球是其中之一。 | 与问题无关 | —— | —— |
| 生成答案1 | 地球自转使得地球表面出现昼夜变化,还影响了风的流向。 | —— | 与用户提问高度相关 | 与资料A高度一致,事实准确 |
| 生成答案2 | 地球是太阳系的第三颗行星。 | —— | 未回答自转的影响,相关性较差 | 与资料B一致,但不回答问题 |
结论说明:
- 答案1 与资料A在事实上一致,并直接回应了用户问题,是高质量产出。
- 答案2 虽然和资料B一致,但没有回答“自转的影响”,相关性不足。
2.5 评估方式 #
在实际操作中,相关性和一致性的判断往往需要较强的语义理解能力。
人工评估虽然精确,但耗时且成本较高。
近年来,借助大语言模型自动化评估相关性和事实一致性,已成为一种高效的替代方案,能够在保证准确性的同时大幅提升评估效率。
3. 评估流程 #
在明确了RAG系统的评测标准后,完整的评估流程通常可以分为三个主要阶段。
首先,需要准备一套专门用于评测RAG系统的测试集。这一数据集应包含一系列具有代表性的问题,以及每个问题对应的权威参考答案。例如,在医疗问答场景下,测试集可以由常见的健康咨询问题及其标准医学解答组成。
第二步,需明确具体的评估指标。这些指标可以是前文提到的RAG评测通用标准,也可以根据实际业务需求进行细化和扩展。常见的评估维度包括答案的准确率、相关性、覆盖度等。
最后,进入评测执行阶段。此时,将测试集中的问题逐一输入到RAG系统中,系统会返回检索到的上下文和生成的答案。评测工具会自动对比系统输出与标准答案,计算各项指标的得分。整个流程的核心在于如何科学、客观地量化系统的表现,从而为后续优化提供数据支撑。
通过这三步,开发者能够系统性地评估RAG系统在特定场景下的实际效果,并据此持续迭代提升模型性能。
4. RAG评测工具 #
RAGAs于2023年发布,旨在实现自动化的RAG系统评测。其初衷是打造一个无需人工参考答案的无监督评估体系,从而大幅降低人工标注的工作量。
不过,随着版本的迭代,部分最新指标已引入了人工标准答案,以提升评测的准确性。
显然,拥有标准答案有助于获得更为可靠的评估结果。
RAGAs的另一大亮点在于充分利用大语言模型(LLM)的推理能力,综合考察问题、答案与上下文三者之间的关联性,并据此计算各项评测指标。
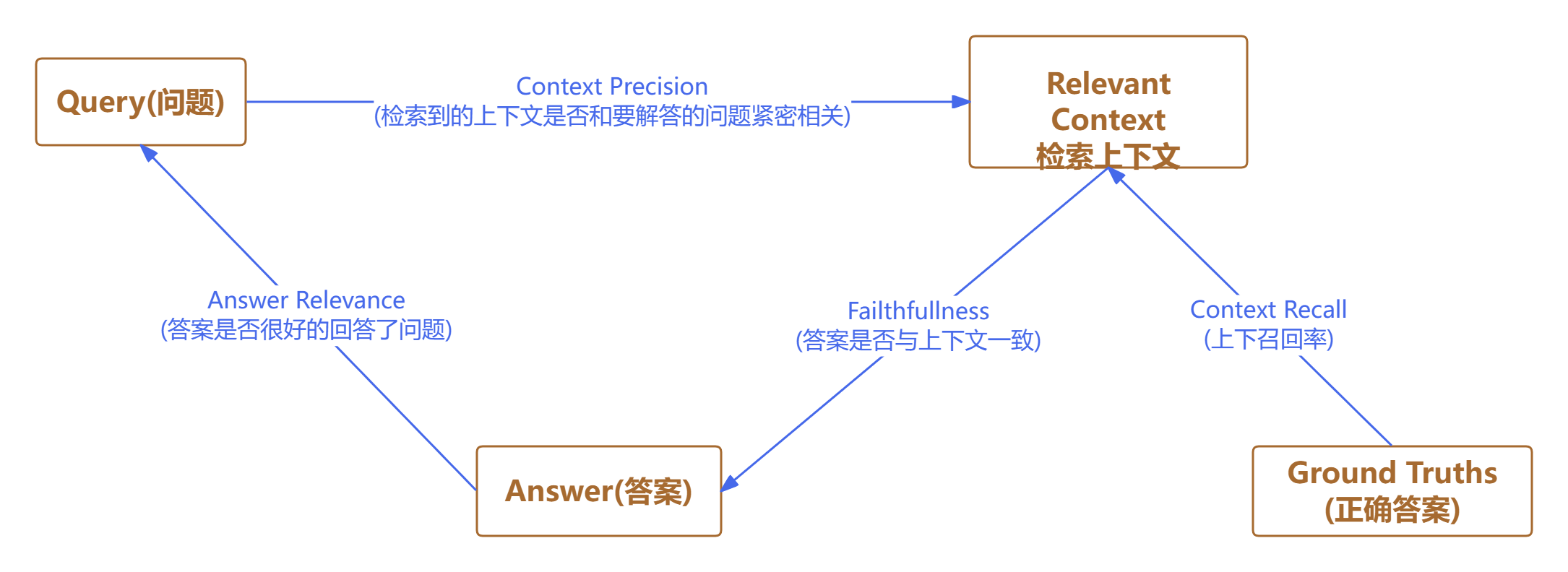
4.1 Context Precision(上下文精度) #
4.1.1. 核心定义 #
Context Precision 衡量的是:检索器返回的上下文列表中,与当前问题真正相关的文档所占的比例和排序质量。
它不只关心“有多少相关文档”,还关心“相关文档是否排在了前面”。
4.1.2. 计算公式与步骤 #
对于每个查询 $ q $:
定义基础变量:
- $ K $:检索返回的上下文片段总数
- $ \text{rel}_k $:第 $ k $ 个片段是否相关(相关=1,不相关=0)
- $ P@k $:前 $ k $ 个片段的精度
计算每个位置的精度: $$ P@k = \frac{\text{前k个片段中相关的数量}}{k} $$
计算Context Precision: $$ \text{Context Precision} = \frac{\sum_{k=1}^{K} (P@k \times \text{rel}_k)}{\text{总相关片段数}} $$ 如果总相关片段数为0,则Context Precision = 0。
4.1.3. 具体计算示例 #
假设检索器返回5个片段(K=5),相关性判断如下:
| 位置k | 片段 | 是否相关(relₖ) | 前k个相关数量 | P@k | P@k × relₖ |
|---|---|---|---|---|---|
| 1 | Doc A | 1 | 1 | 1.0 | 1.0 |
| 2 | Doc B | 0 | 1 | 0.5 | 0.0 |
| 3 | Doc C | 1 | 2 | 0.67 | 0.67 |
| 4 | Doc D | 0 | 2 | 0.5 | 0.0 |
| 5 | Doc E | 1 | 3 | 0.6 | 0.6 |
计算:
- 总相关片段数 = 3
- 分子 = 1.0 + 0.0 + 0.67 + 0.0 + 0.6 = 2.27
- Context Precision = 2.27 / 3 ≈ 0.7567
4.1.4. 设计逻辑与特点 #
为什么要这样设计?
奖励排名质量:
- 相关文档排得越靠前,贡献的 $ P@k $ 值越大
- 第一个相关文档的 $ P@k $ = 1.0,贡献最大
- 最后一个相关文档的 $ P@k $ 较小,贡献也小
惩罚不相关文档:
- 不相关文档会稀释精度,降低后续 $ P@k $ 值
- 如果前面有很多不相关文档,会显著降低得分
归一化处理:
- 除以总相关数,使得不同查询间的得分可比
4.1.5. 极端情况分析 #
情况1:完美检索(所有相关文档排在最前)
相关性序列:[1, 1, 1, 0, 0]
计算:P@1=1.0×1 + P@2=1.0×1 + P@3=1.0×1 + ... = 3.0/3 = 1.0
得分:1.0情况2:最差检索(相关文档全在最后)
相关性序列:[0, 0, 0, 1, 1]
计算:P@4=0.25×1 + P@5=0.4×1 = 0.65/2 = 0.325
得分:0.325情况3:混合情况(相关文档分散)
相关性序列:[1, 0, 1, 0, 1]
计算:P@1=1.0×1 + P@3=0.67×1 + P@5=0.6×1 = 2.27/3 ≈ 0.7567
得分:0.7574.1.6. 在RAG评估中的意义 #
- 高Context Precision:检索器能准确找到相关文档并优先返回
- 低Context Precision:要么检索不准(找到不相关文档),要么排序不好(相关文档排后面)
这个指标直接影响到后续LLM生成答案的质量,因为LLM通常更关注排在前面的上下文。
4.2 Faithfulness(忠实性指标) #
4.2.1. 核心定义 #
Faithfulness 关注的是生成答案与检索上下文之间的事实一致性。一个忠实的答案应该:
- 所有声明都能在上下文中找到支持
- 不包含上下文中未提及的事实或信息
- 不对上下文信息进行过度解读或扭曲
4.2.2. 计算方法 #
Faithfulness通常通过以下流程计算:
4.2.2.1 步骤1:从生成答案中提取声明 #
将生成的答案分解为独立的、可验证的事实声明。
示例: 生成答案:"爱因斯坦在1905年发表了狭义相对论,并因此获得诺贝尔奖。" → 提取声明:
- "爱因斯坦发表了狭义相对论"
- "狭义相对论发表于1905年"
- "爱因斯坦因狭义相对论获得诺贝尔奖"
4.2.2.2 步骤2:验证每个声明的支持性 #
检查每个声明是否能在提供的上下文中找到直接或间接的支持。
验证标准:
- 完全支持:声明在上下文中明确提及或逻辑推导得出
- 部分支持:声明部分正确但包含额外信息
- 不支持:声明在上下文中完全找不到依据
- 矛盾:声明与上下文信息直接冲突
4.2.2.3 步骤3:计算Faithfulness得分 #
$$ \text{Faithfulness} = \frac{\text{支持的声明数量}}{\text{总声明数量}} $$
4.2.3. 具体计算示例 #
上下文:"阿尔伯特·爱因斯坦于1905年提出了狭义相对论,该理论包含了著名的质能方程E=mc²。"
生成答案:"爱因斯坦在1905年提出狭义相对论,其中包含质能方程E=mc²,这是他获得诺贝尔奖的主要贡献。"
步骤1:提取声明
- "爱因斯坦在1905年提出狭义相对论"
- "狭义相对论包含质能方程E=mc²"
- "狭义相对论是爱因斯坦获得诺贝尔奖的主要贡献"
步骤2:验证支持性
- 声明1:完全支持(上下文明确提及)
- 声明2:完全支持(上下文明确提及)
- 声明3:不支持(上下文未提及诺贝尔奖)
步骤3:计算得分 $$ \text{Faithfulness} = \frac{2}{3} \approx 0.667 $$
4.3 Answer relevance(回答相关性) #
4.3.1. 核心定义 #
Answer Relevance 衡量的是:生成的答案在多大程度上直接回答了原始问题,而不考虑答案的事实正确性。
它评估的是答案的:
- 相关性:是否针对问题主题
- 完整性:是否回答了问题的核心诉求
- 简洁性:是否避免无关信息
4.3.2. 计算方法 #
4.3.2.1 基于LLM的评估方法 #
通过让LLM评判员对答案相关性进行评分:
def calculate_answer_relevance(question, generated_answer):
prompt = f"""
请评估以下答案对问题的相关性。
问题:{question}
生成答案:{generated_answer}
请从1-5分进行评分:
5 - 答案完全直接回答问题,高度相关且完整
4 - 答案基本回答问题,包含相关信息但略有不足
3 - 答案部分相关,但遗漏了关键方面或包含不必要信息
2 - 答案相关性很低,只有少量相关信息
1 - 答案完全不相关或回避问题
只返回分数数字。
"""
# 调用LLM API获取评分
return score4.3.2.1.1 得分标准化 #
将1-5分标准化到0-1范围: $$ \text{Answer Relevance} = \frac{\text{LLM评分} - 1}{4} $$
4.3.2.1.2 具体评分标准 #
5分(完美相关)
- 答案直接、完整地回答了问题的所有方面
- 没有无关信息或冗余内容
- 逻辑清晰,重点突出
示例: 问题:"苹果公司成立于哪一年?" 答案:"苹果公司成立于1976年。" 评分:5 → 标准化:1.0
4分(高度相关)
- 答案回答了核心问题
- 可能遗漏了次要细节或包含少量不必要信息
示例: 问题:"苹果公司成立于哪一年?" 答案:"苹果公司由史蒂夫·乔布斯等人于1976年创立,是一家科技公司。" 评分:4 → 标准化:0.75
3分(部分相关)
- 答案涉及问题主题但不够直接
- 可能包含较多无关信息或遗漏关键点
示例: 问题:"苹果公司成立于哪一年?" 答案:"苹果公司是一家美国科技公司,创始人包括乔布斯,在科技行业很有影响力。" 评分:3 → 标准化:0.5
2分(低度相关)
- 只有少量相关信息
- 大部分内容与问题无关
示例: 问题:"苹果公司成立于哪一年?" 答案:"科技行业发展很快,很多公司都在创新。" 评分:2 → 标准化:0.25
1分(完全不相关)
- 答案完全回避问题或毫无关联
示例: 问题:"苹果公司成立于哪一年?" 答案:"今天天气很好,适合户外运动。" 评分:1 → 标准化:0.0
4.3.2.1 基于相似度的计算方法 #
另一种方法是计算问题与生成答案的语义相似度:
# 导入SentenceTransformer用于提取句子嵌入向量
from sentence_transformers import SentenceTransformer
# 导入余弦相似度计算函数
from sklearn.metrics.pairwise import cosine_similarity
# 定义函数用于计算问题与答案的相关性相似度
def calculate_answer_relevance_similarity(question, answer):
# 加载预训练的句子嵌入模型
model = SentenceTransformer('all-MiniLM-L6-v2')
# 对问题进行编码,获得嵌入向量
question_embedding = model.encode([question])
# 对答案进行编码,获得嵌入向量
answer_embedding = model.encode([answer])
# 计算问题和答案向量之间的余弦相似度
similarity = cosine_similarity(question_embedding, answer_embedding)[0][0]
# 返回相似度分数
return similarity4.3.3. 具体计算示例 #
4.3.3.1 示例1:高度相关 #
问题:"Python的主要特点是什么?" 生成答案:"Python的主要特点包括简洁易读的语法、动态类型、解释型语言、丰富的标准库和跨平台兼容性。"
评估:
- 直接回答了问题的所有方面
- 没有无关信息
- LLM评分:5 → Answer Relevance:1.0
4.3.3.2 示例2:部分相关 #
问题:"Python的主要特点是什么?" 生成答案:"Python是一种编程语言,有很多库可以用,比如NumPy和Pandas,适合数据科学。"
评估:
- 涉及主题但不够全面
- 遗漏了语法简洁、动态类型等关键特点
- 包含了具体库名等不必要细节
- LLM评分:3 → Answer Relevance:0.5
4.3.3.3 示例3:低相关性 #
问题:"Python的主要特点是什么?" 生成答案:"编程语言有很多种,Java、C++、JavaScript都很流行。"
评估:
- 几乎没有针对Python特点的信息
- LLM评分:2 → Answer Relevance:0.25
4.4 Context Recall(上下文召回率) #
4.4.1. 核心定义 #
Context Recall 衡量的是:检索器返回的上下文中包含了多少回答问题所需的全部相关信息。
它评估的是检索器的:
- 覆盖度:是否找到了所有关键信息片段
- 完整性:是否遗漏了重要相关内容
- 召回能力:从全部相关文档中找出了多少比例
4.4.2. 计算方法 #
基于人工标注的黄金标准
计算公式: $$ \text{Context Recall} = \frac{\text{检索上下文中的相关片段数量}}{\text{所有相关片段总数}} $$
或者更精确地: $$ \text{Context Recall} = \frac{|{\text{相关片段}} \cap {\text{检索片段}}|}{|{\text{相关片段}}|} $$
4.4.3. 具体计算步骤 #
4.4.3.1 步骤1:建立黄金标准 #
人工标注所有可能相关的文档片段,构建"理想答案"所需的完整上下文集合。
4.4.3.2 步骤2:运行检索 #
使用RAG检索器获取实际返回的上下文片段。
4.4.3.3 步骤3:计算召回率 #
比较检索结果与黄金标准的重叠程度。
4.4.4. 具体计算示例 #
假设一个问题有5个相关的黄金标准片段:
- 相关片段集合 = {片段A, 片段B, 片段C, 片段D, 片段E}
情况1:完美检索
检索结果:{片段A, 片段B, 片段C, 片段D, 片段E}
Context Recall = 5/5 = 1.0情况2:部分检索
检索结果:{片段A, 片段C, 片段E}
Context Recall = 3/5 = 0.6情况3:较差检索
检索结果:{片段A}
Context Recall = 1/5 = 0.2情况4:包含不相关内容的检索
检索结果:{片段A, 片段B, 片段X, 片段Y, 片段Z}
Context Recall = 2/5 = 0.4注意:不相关片段不影响召回率计算
4.4.5. 基于LLM的自动化评估 #
在实际评估中,通常使用LLM来自动化计算:
def calculate_context_recall(question, retrieved_contexts, ground_truth_answer):
prompt = f"""
基于给定的问题和参考答案,评估检索到的上下文是否包含了参考答案所需的所有关键信息。
问题:{question}
参考答案:{ground_truth_answer}
检索到的上下文:{retrieved_contexts}
请分析:
1. 参考答案依赖于哪些关键信息点
2. 这些信息点有多少在检索上下文中出现
3. 计算召回率:出现的关键信息点数量 / 总关键信息点数量
返回格式:召回率分数(0-1之间的浮点数)
"""
# 调用LLM API并解析结果
return recall_score4.4.6. 具体场景示例 #
示例:历史问题
问题:"第二次世界大战的主要参战国有哪些?"
黄金标准相关信息:
- 轴心国:德国、意大利、日本
- 同盟国:美国、英国、苏联、中国、法国
- 其他重要参战国:加拿大、澳大利亚等
检索结果1(高召回率):
- 包含:德国、意大利、日本、美国、英国、苏联、中国
- Context Recall = 7/8 ≈ 0.875(假设8个关键国家)
检索结果2(低召回率):
- 包含:德国、日本、美国、英国
- Context Recall = 4/8 = 0.5